tidyverse ile makroekonomik analiz
Bu yazıda tidyverse paketini kullanacağım. tidyverse aslında tek bir paket olmayıp, birçok paketi barındıran bir tür paketler paketi. İçerisinde ggplot2, dplyr, readr, tidyr gibi sık kullanılan paketler bulunmaktadır. Dolayısıyla bu mütevazi notta %5’inin bile anlatılması zor olup sadece %>% operatörü ve filter() fonksiyonunu kullanarak paketin sağladığı kolaylıkların ne menem bir şey olduğuna işaret etmeye çalışacağım.
Bilindiği üzere R sistemi (base hariç) dünyanın dört bir yanında yaşayan gönüllülerce geliştirilmektedir. Bu özelliği R’a dinamizm ve zenginlik katmaktadır. İhtiyaç duyabileceğimiz bir paketin birileri tarafından zaten geliştirilmiş olması yüksek ihtimale sahiptir. CRAN sayfasında 6.000’in üzerinde paket bulunmaktadır. Ancak bu durumun olumsuz tarafı R paketlerinde (hatta kısmen base paketinde bile) standart bir dilin tutturalamamış olmasıdır. Bu özellik (fark etsek de, fark etmesek de) hata mesajları olarak sıkça karşımıza çıkmakta. Bu sebeple etkin R kullanımı için veri yapılarının, fonksiyonların ve bunlara ilişkin istisnai durumların inceliklerine hakim olmamız gerekmektedir.
İşte tidyverse bu olumsuzluğun önüne geçmek ve verisetlerinin manipülasyonunda standart bir dil kullanabilmek ve hatta kolaylaştırmak amacıyla üretilmiş. “Ben zaten standart R gramerine ve fonksiyonlarına hakimim, her tür işlemi gözüm kapalı yapıyorum” diyorsanız bile tidyverse işlemlerinizi hızlandıracaktır. Temel R diliyle uzun kod satırları gerektiren bazı işlemler tidyverse ile daha az kodla yapılabilir. Bu sebeple ortalamanın üstü kullanıcıların da tidyverse paketine bir göz atmalarında fayda var.
Bu yazıda tidyverse paketini, CRAN üzerinden indirebileceğimiz ameco verisetiyle birlikte kullanacağım. ameco Avrupa Komisyonunca derlenen makroekonomik verileri içeren bir verisetidir. Genellikle 1960’lardan başlayan zaman serisi tarzı veriler içermektedir. Ekonomik haberlerin gündemin üst sıralarında olduğu bu dönemde bazı makroekonomik verilere grafikler yardımıyla bir bakalım.
library(tidyverse)
library(ameco)İlk olarak başımızın belası olan dış ticaret açığının tarihi seyrini inceleyeceğim. Bunun için ameco verisetini filtreleyerek Türkiyeye ait ithalat ve ihracat rakamlarını (2010 fiyatlarıyla) içeren yeni bir veriseti oluşturacağım:
exim <- ameco %>%
filter((sub.chapter == "01 Exports of goods and services" |
sub.chapter == "02 Imports of goods and services") &
(title == "Exports of goods and services at 2010 prices" |
title =="Imports of goods and services at 2010 prices") &
(cntry == "TUR"))Burada pipe olarak adlandırılan %>% operatörünü kulandık. %>% operatörü ile bir önceki kodun çıktısının, bir sonraki kod için girdi olarak kullanılabildiği iç içe kod yazarak kod yazımını ve bellek kullanımını azaltabiliriz.
Şimdi bu alt verisetiyle ithalat ve ihracatın seyrine grafikle bakabiliriz:
ggplot(exim, aes(year, value, color=sub.chapter)) +
guides(color = guide_legend(title=NULL)) +
scale_color_discrete(labels = c("İhracat","Ithalat")) +
geom_freqpoly(stat = "identity") +
xlab(NULL) + ylab("2010 fiyatlarıyla miktar")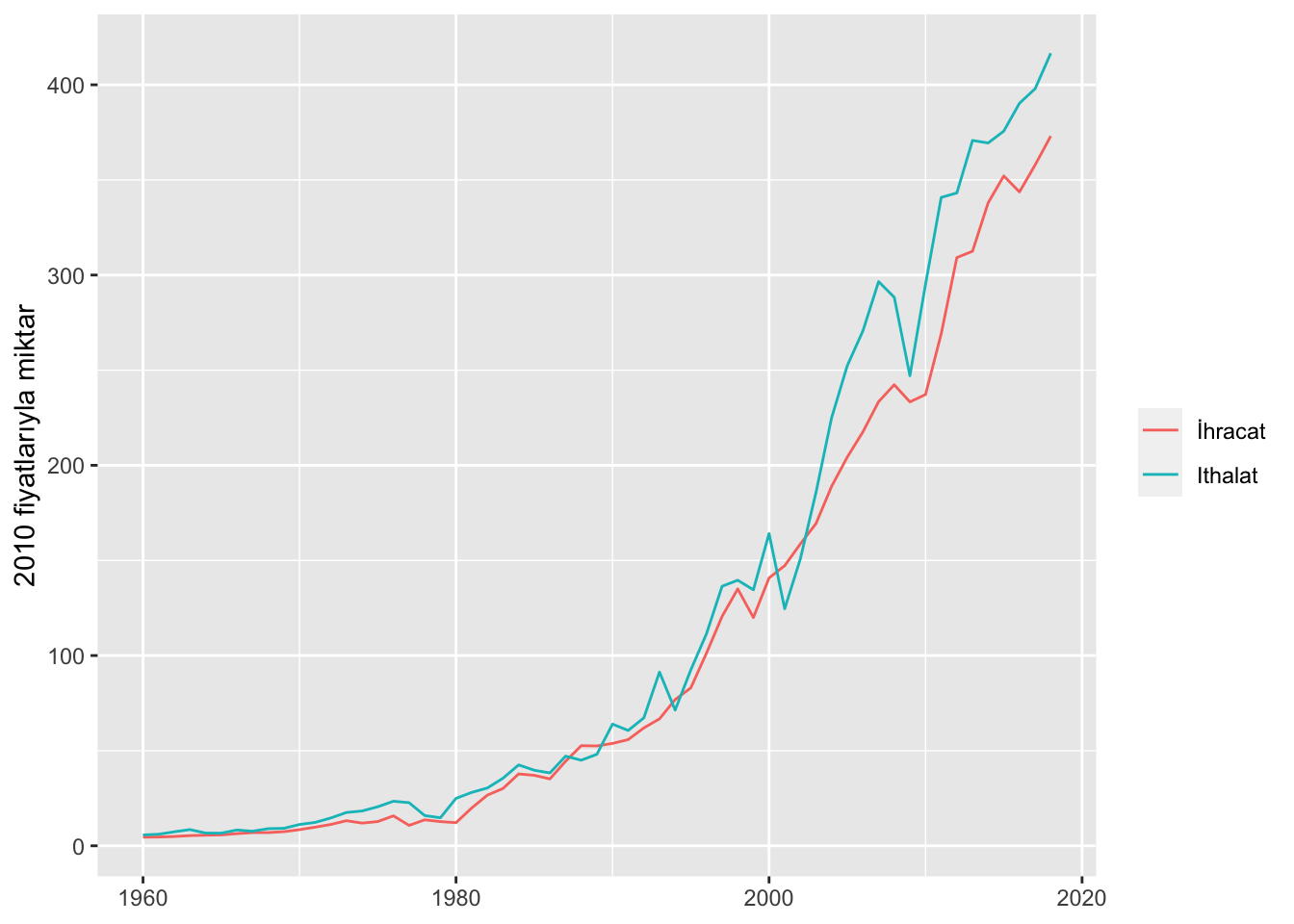
R’ın standart grafiklerini sevenler için aynı grafik şu şekilde çizilebilir:
plot(exim$value[exim$sub.chapter == "02 Imports of goods and services"]
~exim$year[exim$sub.chapter == "02 Imports of goods and services"],
type = "l",xlab="",ylab = "2010 fiyatlarıyla miktar")
x <- exim$value[exim$sub.chapter == "01 Exports of goods and services"]
y <- exim$year[exim$sub.chapter == "01 Exports of goods and services"]
lines(x~y,lty=2)
legend(1960,400, c("ithalat", "ihracat"), lty = c(1,2))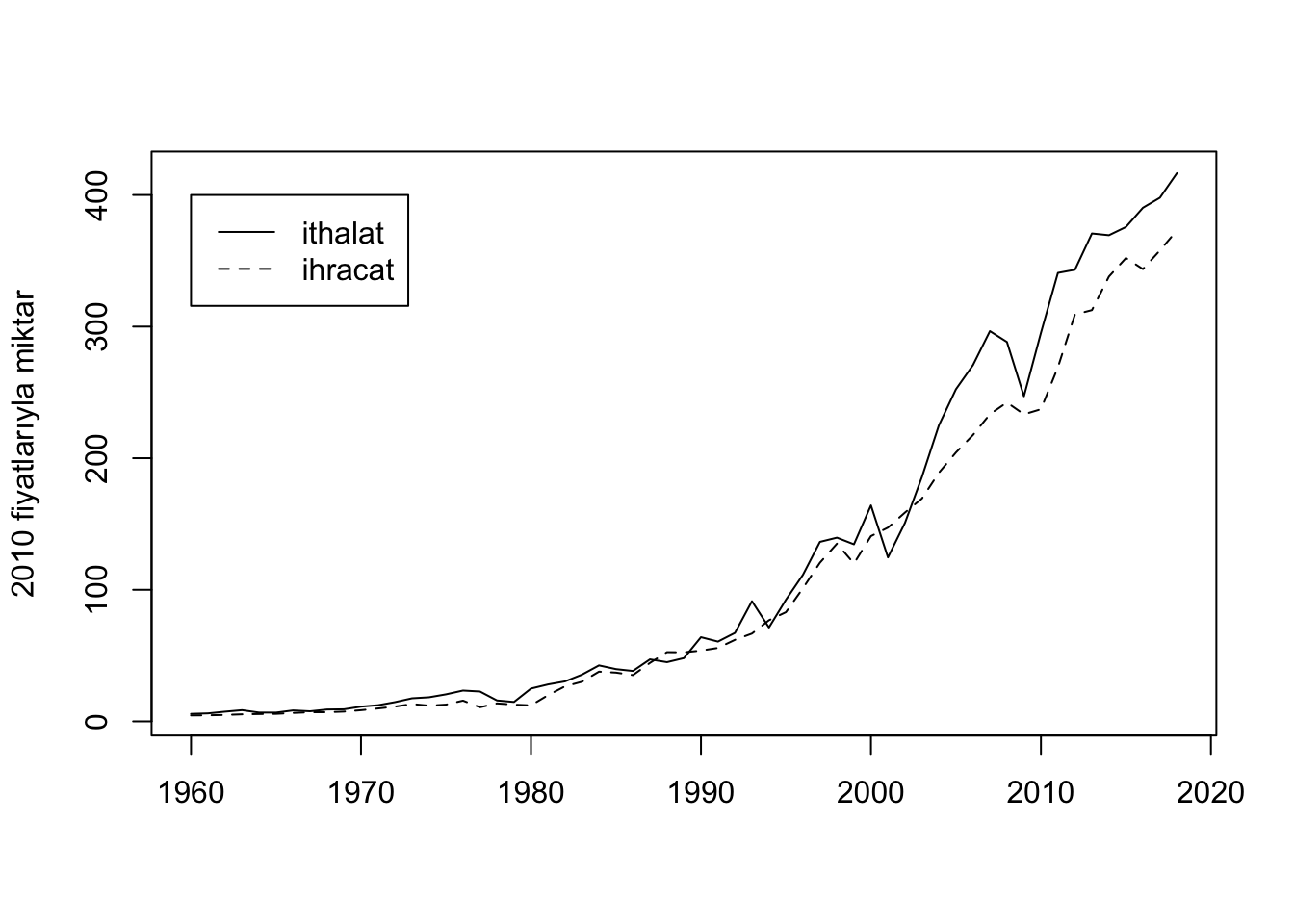
Görüldüğü gibi özellikle 2001 ekonomik krizinin ardından ithalat rakamları ihracatı geçmeye başlamış, 2007-2008 yılında birbirlerine yaklaşmış ancak sonrasında makas tekrar açılmış.
Ticaret hacmine göre ülkelerin durumunu karşılaştırmak için öncelikle ilgili alt verisetini üretelim:
ftrade <- ameco %>%
filter(sub.chapter == "02 Foreign trade shares in world trade" &
title == "Average share of imports and exports of goods in world trade including intra EU trade :- Foreign trade statistics" &
cntry != "EU28" & cntry != "EU15" & cntry != "EA19" &
cntry != "EA12" & cntry != "DU15" & cntry != "DA12")Ülkelerin ticaret hacmini zaman serisi olarak karşılaştırmak zor çünkü verisetinde 43 farklı ülke var. Bunun yerine mevcut verilerin ortalamalarını alıp büyükten küçüğe sıralanmış grafiğini çizeceğim:
by_value <- group_by(ftrade, cntry)
by_avrg <- summarise(by_value, avrg = mean(value, na.rm = T))## `summarise()` ungrouping output (override with `.groups` argument)by_avrg <- arrange(by_avrg,avrg)
by_avrg <- by_avrg[by_avrg$cntry != "D",]
ggplot(by_avrg,aes(x=avrg,y=reorder(cntry,avrg))) +
geom_point() +xlab(NULL) + ylab(NULL) +
theme_bw()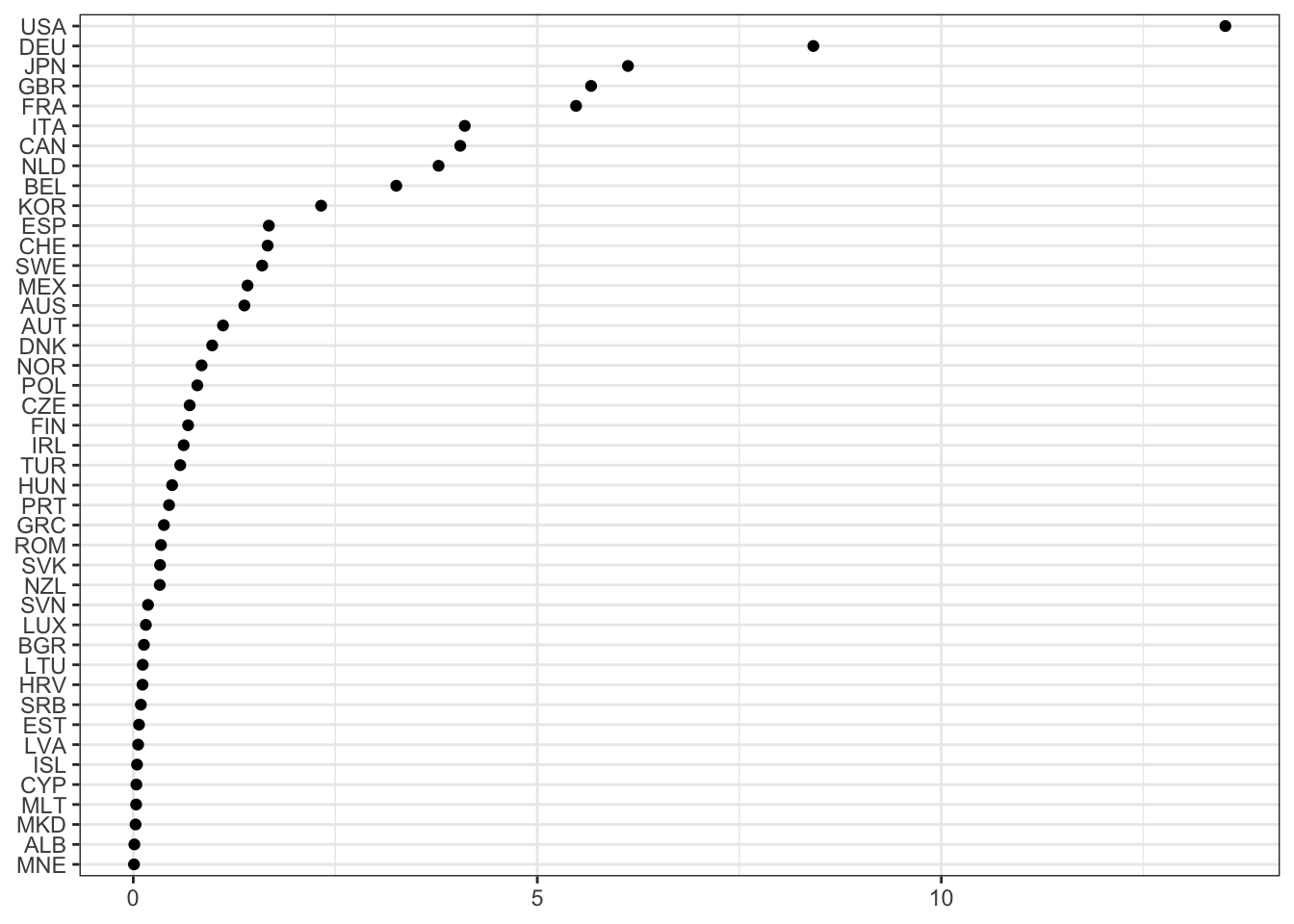
ABD, Almanya, Japonya, İngiltere ve Fransa başı çekerken Türkiye ortalarda bulunmaktadır.
Sektörlere göre işgücü rakamlarını hesaplamak için yine alt verisetini üretiyoruz ve grafik başlıklarını Türkçeleştirmek için (maalesef) değişkenleri yeniden isimlendiriyoruz:
emplymnt <- ameco %>%
filter(sub.chapter == "01 Employment, persons" &
cntry == "TUR" & year >= 2003 & year < 2013)
emplymnt1 <- emplymnt
emplymnt1$title[emplymnt1$title == "Employment, persons: agriculture, forestry and fishery products (National accounts)"] <- "Tarım, orman ve balıkçılık"
emplymnt1$title[emplymnt1$title == "Employment, persons: industry excluding building and construction (National accounts)"] <- "Sanayi"
emplymnt1$title[emplymnt1$title == "Employment, persons: building and construction (National accounts)"] <- "İnşaat"
emplymnt1$title[emplymnt1$title == "Employment, persons: services (National accounts)"] <- "Hizmetler"
emplymnt1$title[emplymnt1$title == "Employment, persons: manufacturing industry (National accounts)"] <- "İmalat"
ggplot(emplymnt1, aes(year, value)) +
geom_line() +
facet_wrap(~title, nrow = 3)## Warning: Removed 2 row(s) containing missing values (geom_path).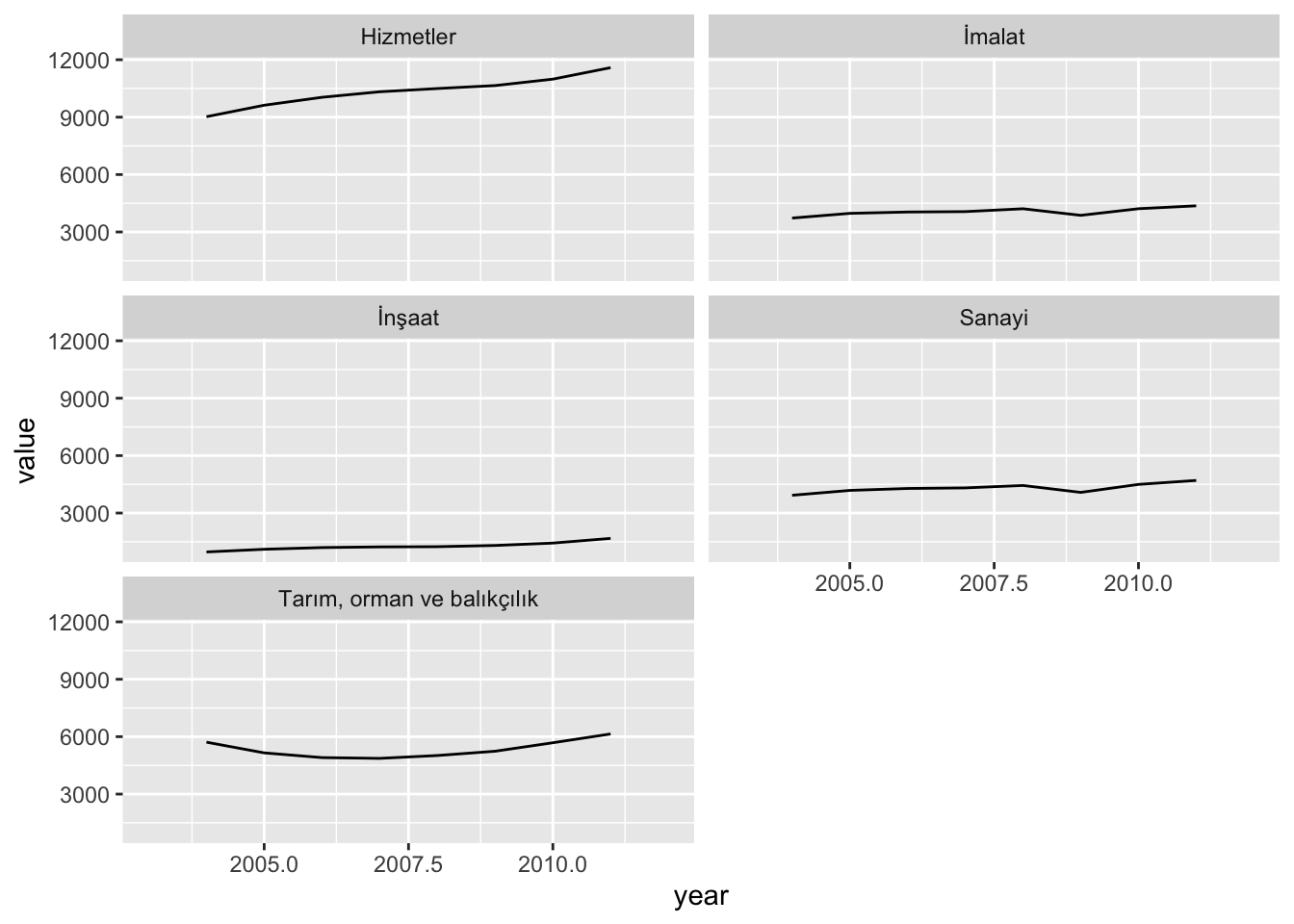
Mevcut işgücü istatistikleri hizmetler sektöründeki artışın dışında diğer sektörlerde belirgin bir farklılaşmanın olmadığını gösteriyor.
En önemli makroekonomik göstergelerden birisi de işsizlik oranları. Ülkemizde işsizliğin seyrine AB ülkeleriyle karşılaştırmalı olarak bakalım:
unemp <- ameco %>%
filter(sub.chapter == "03 Unemployment" &
title == "Unemployment rate: total :- Member States: definition EUROSTAT")
tur_eu_unemp <- unemp %>%
filter(cntry == "TUR" | cntry == "DU15" | cntry == "EU15" )
ggplot(tur_eu_unemp,aes(year,value,col=cntry)) +
geom_line() +
geom_point() +
xlab(NULL) +
ylab(NULL)## Warning: Removed 58 row(s) containing missing values (geom_path).## Warning: Removed 58 rows containing missing values (geom_point).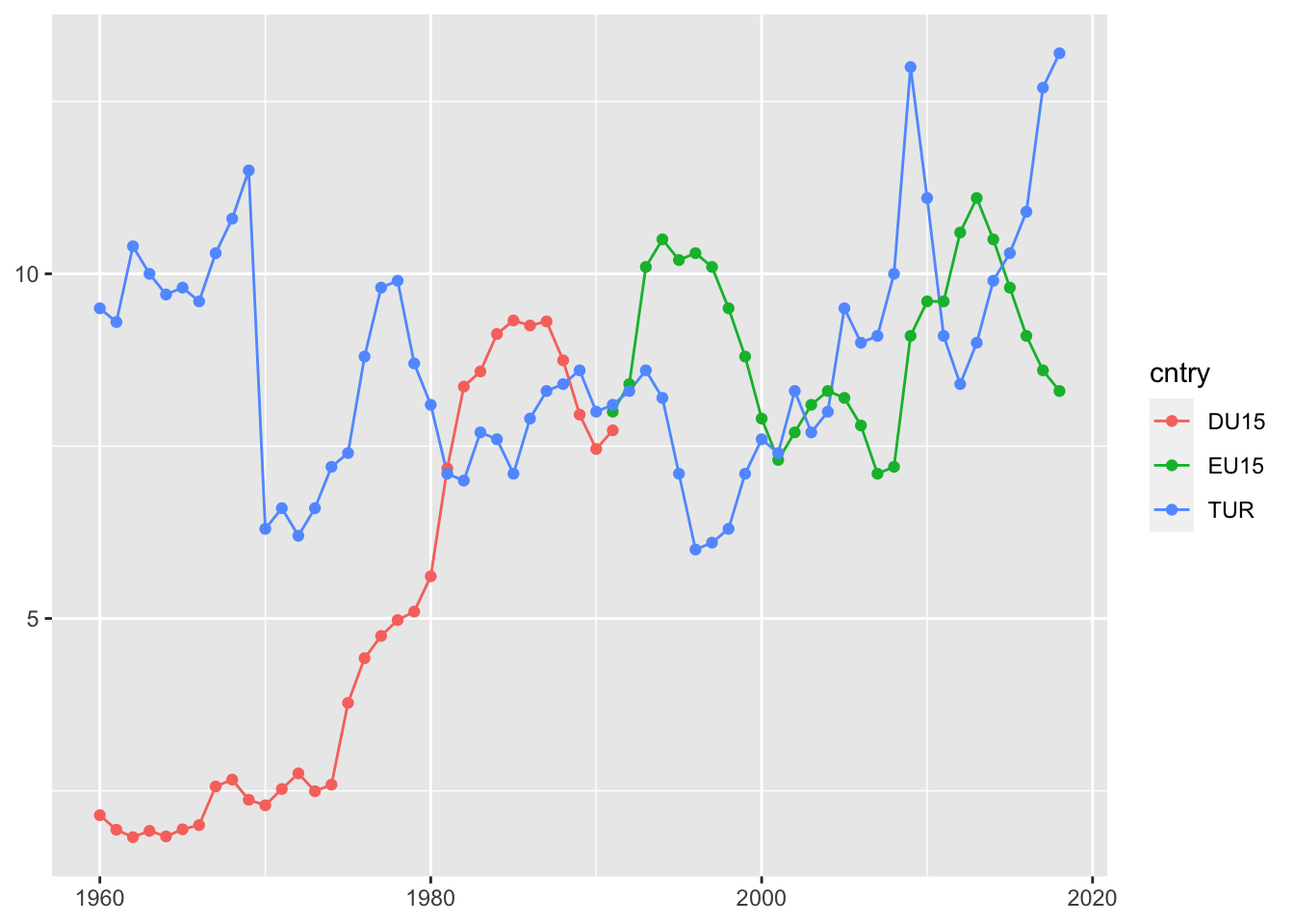
Ekonomik kriz akabinde yeni sağın yükselişi ve yaygınlaşan özelleştirme politikalarının etkisiyle 75’ten itibaren Avrupa’da işsizlik 87’ye kadar yükselmekte ve sonrasında %6 ile %11 arasında dalgalı bir seyir izlemekte.
Ülkemizdeyse ilk dikkat çeken 1969 yılındaki sert düşüş. Bunun sebebi merak uyandırmakta… Sonrasında 75’ten itibaren yükselişe geçen işsizlik 80’lerde tekrar azalarak 2000’e kadar %6 ile %8 aralığında gerçekleşmiş. 2000’den sonra yükselişe geçerek tarihi seviyelerinden olan %13’leri bulmuş görünüyor.
İşsizlikle birlikte bir de tüketim alışkanlıklarını aynı biçimde karşılaştıralım:
consump <- ameco %>%
filter(sub.chapter =="08 Total consumption" &
title == "Total consumption at 2010 prices")
tur_eu_consump <- consump %>%
filter(cntry == "TUR" | cntry == "DU15" | cntry == "EU15")
ggplot(tur_eu_consump, aes(x=year, y=value, col=cntry)) +
geom_line() +
xlab(NULL) +
ylab(NULL)## Warning: Removed 136 row(s) containing missing values (geom_path).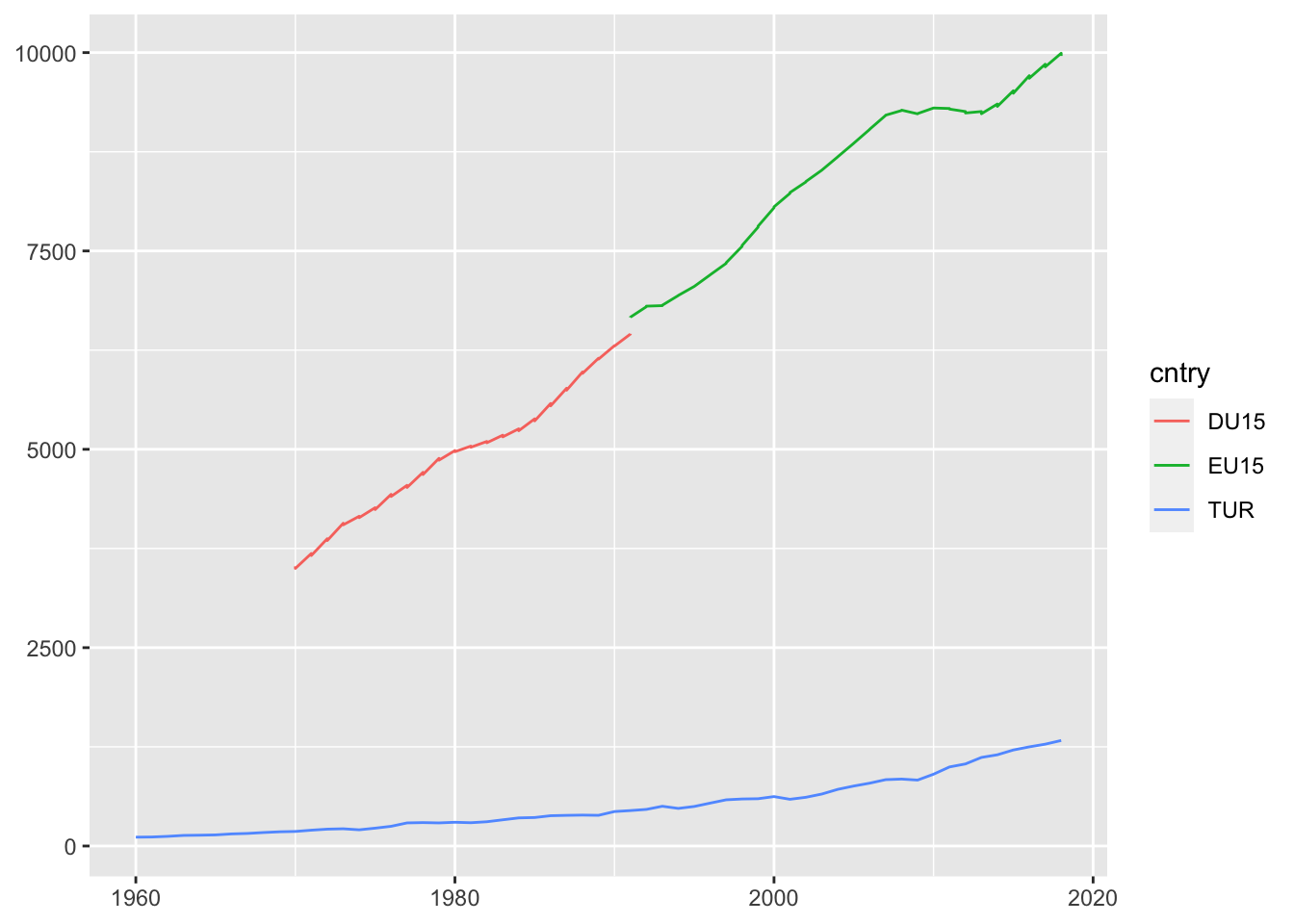
Toplam tüketim miktarı AB ülkelerinde dik bir eğimle artarken Türkiye’de nispeten daha istikrarlı bir artış gözlemlenmektedir. Türkiye’ye daha detaylı bakacak olursak:
tur_consump <- tur_eu_consump %>%
filter(cntry == "TUR")
ggplot(tur_consump, aes(x=year, y=value, col=cntry)) +
geom_line() +
xlab(NULL) +
ylab(NULL)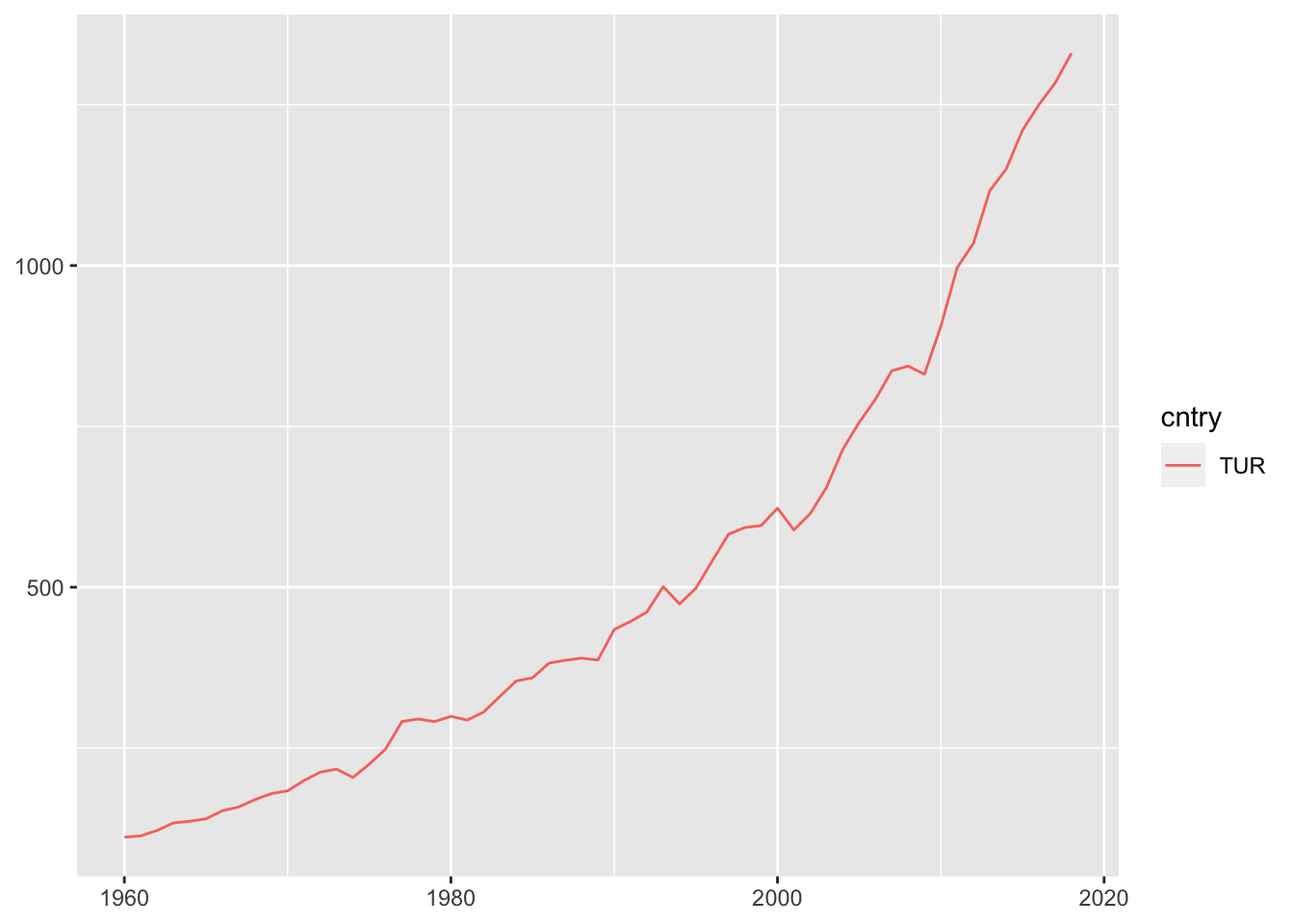
Görüleceği üzere 80’lerden itibaren tüketim hızımız hızlı bir biçimde artmıştır. Kriz dönemleirndeki yavaşlamalara rağmen ivme devam etmiştir.
Tüketime karşın üretim ne alemde? Üretimin önemli göstergelerinden GSMH verilerine bakalım:
gdp_tur_eu <- ameco %>%
filter(sub.chapter =="01 Gross domestic product" &
title == "Gross domestic product at current prices" &
(cntry == "TUR" | cntry == "DU15" | cntry == "EU15") &
(unit == "Mrd ECU/EUR, Standard aggregation" | unit == "Mrd ECU/EUR") &
code != "EU15.1.0.0.0.UVGD" & code != "DU15.1.0.0.0.UVGD")
gdp_tur <- gdp_tur_eu %>%
filter( cntry == "TUR")
ggplot(gdp_tur, aes(x=year, y=value)) +
geom_line() +
geom_point() +
xlab(NULL) +
ylab(NULL)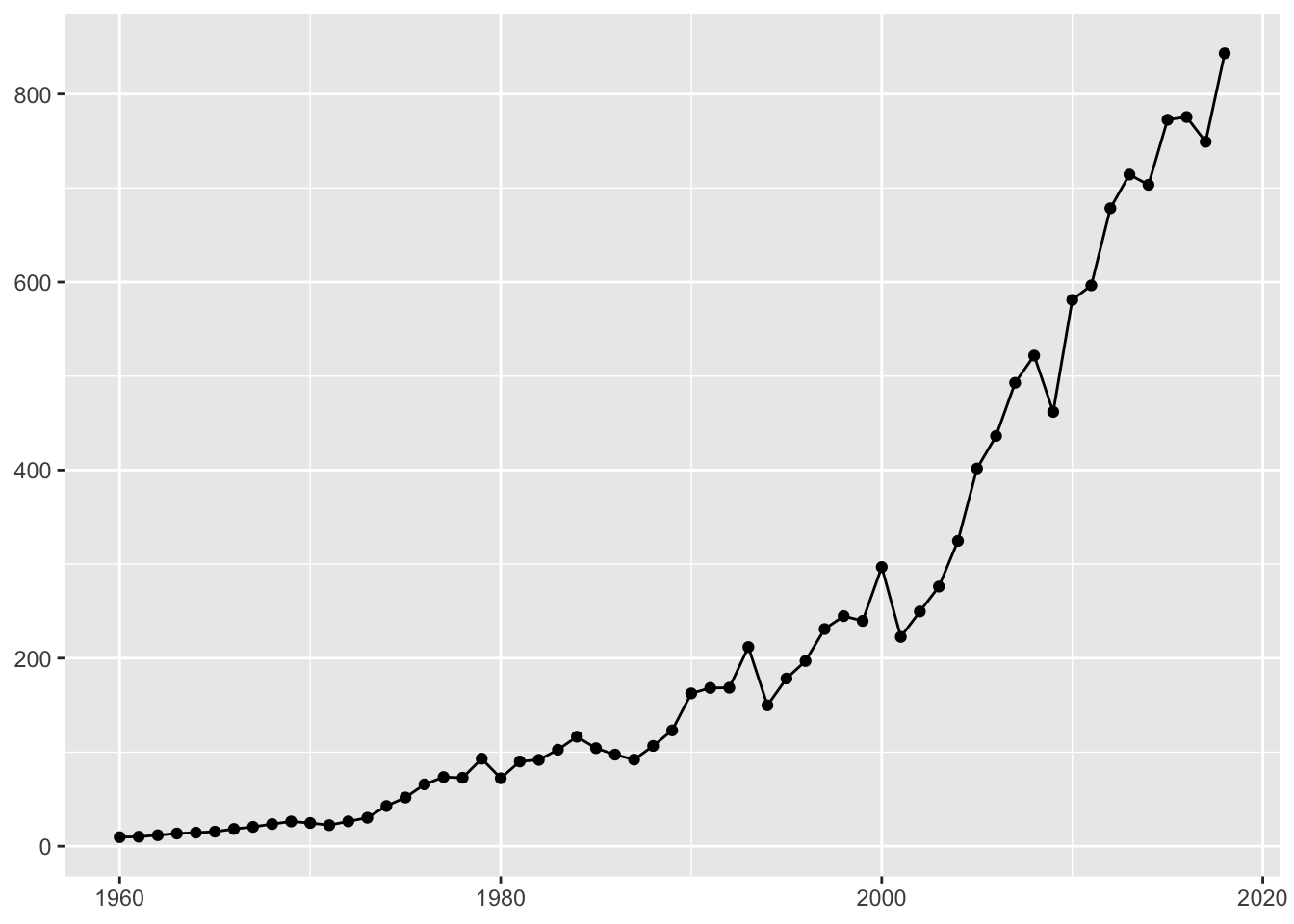
Ülkemizde 90’ların ortalarından itibaren GSMH’de önceki yıllara kıyasla daha hızlı artış olmuştur. Ancak bunu AB ülkeleriyle kıyasladığımızda ufak kaldığı görülecektir:
ggplot(gdp_tur_eu,aes(x=year, y=value, col=cntry)) +
geom_line() +
xlab(NULL) +
ylab(NULL)## Warning: Removed 58 row(s) containing missing values (geom_path).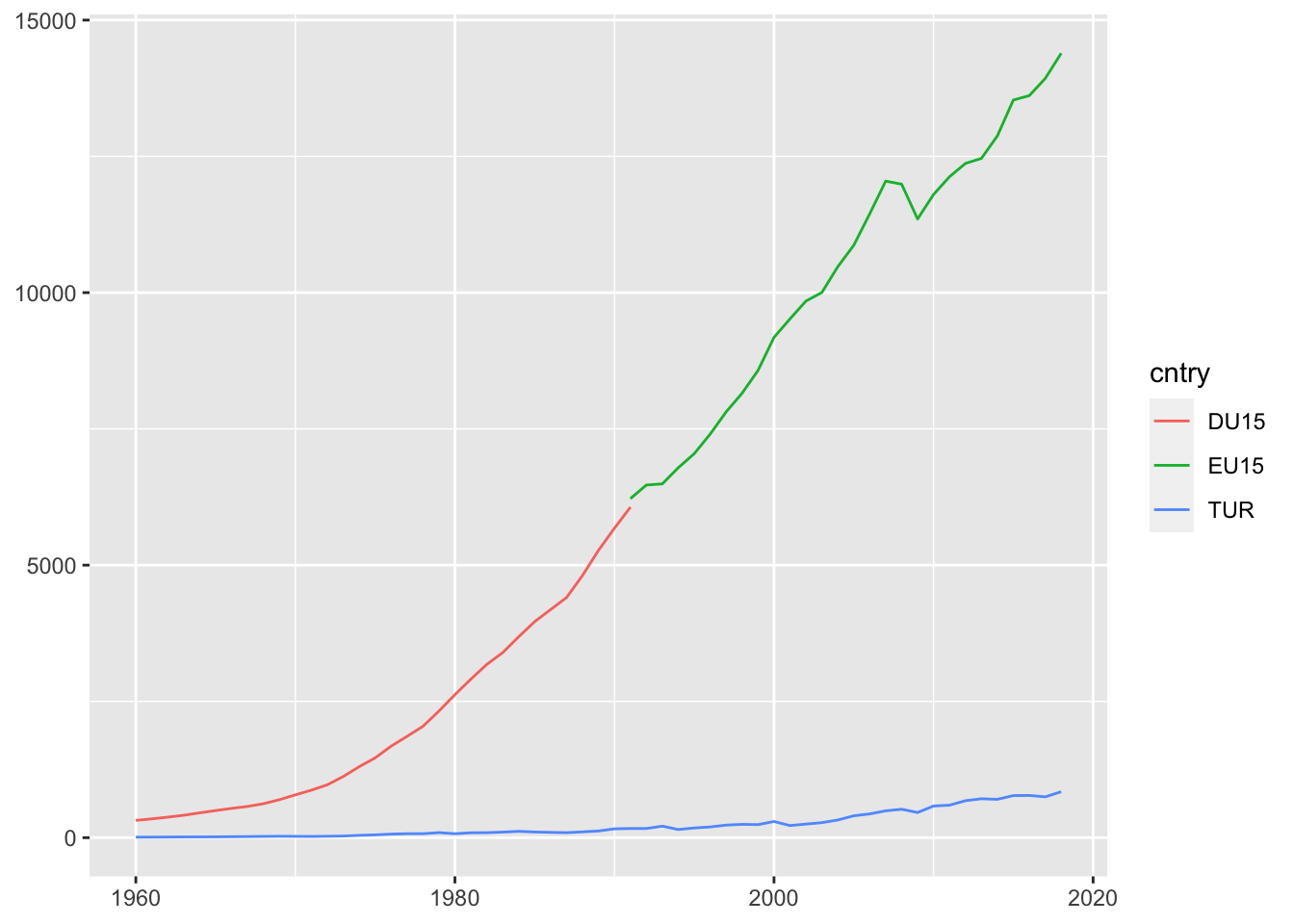
Son olarak alacak verecek hesaplarını inceleyelim:
balance_tur_eu <- ameco %>%
filter(sub.chapter =="01 Balances with the rest of the world, national accounts" &
title == "Net lending (+) or net borrowing (-): total economy" &
(cntry == "TUR" | cntry == "DU15" | cntry == "EU15") &
(unit == "Mrd ECU/EUR, Standard aggregation" | unit == "Mrd ECU/EUR") &
year > 2008 & code != "EU15.1.0.0.0.UBLA")
balance_tur_eu$np <- balance_tur_eu$value > 0
ggplot(balance_tur_eu, aes(year, value, fill = np)) +
geom_bar(stat="identity", position = "identity") +
guides(fill = guide_legend(title=NULL)) +
scale_fill_discrete(labels = c("Türkiye","EU")) +
xlab(NULL) + ylab(NULL)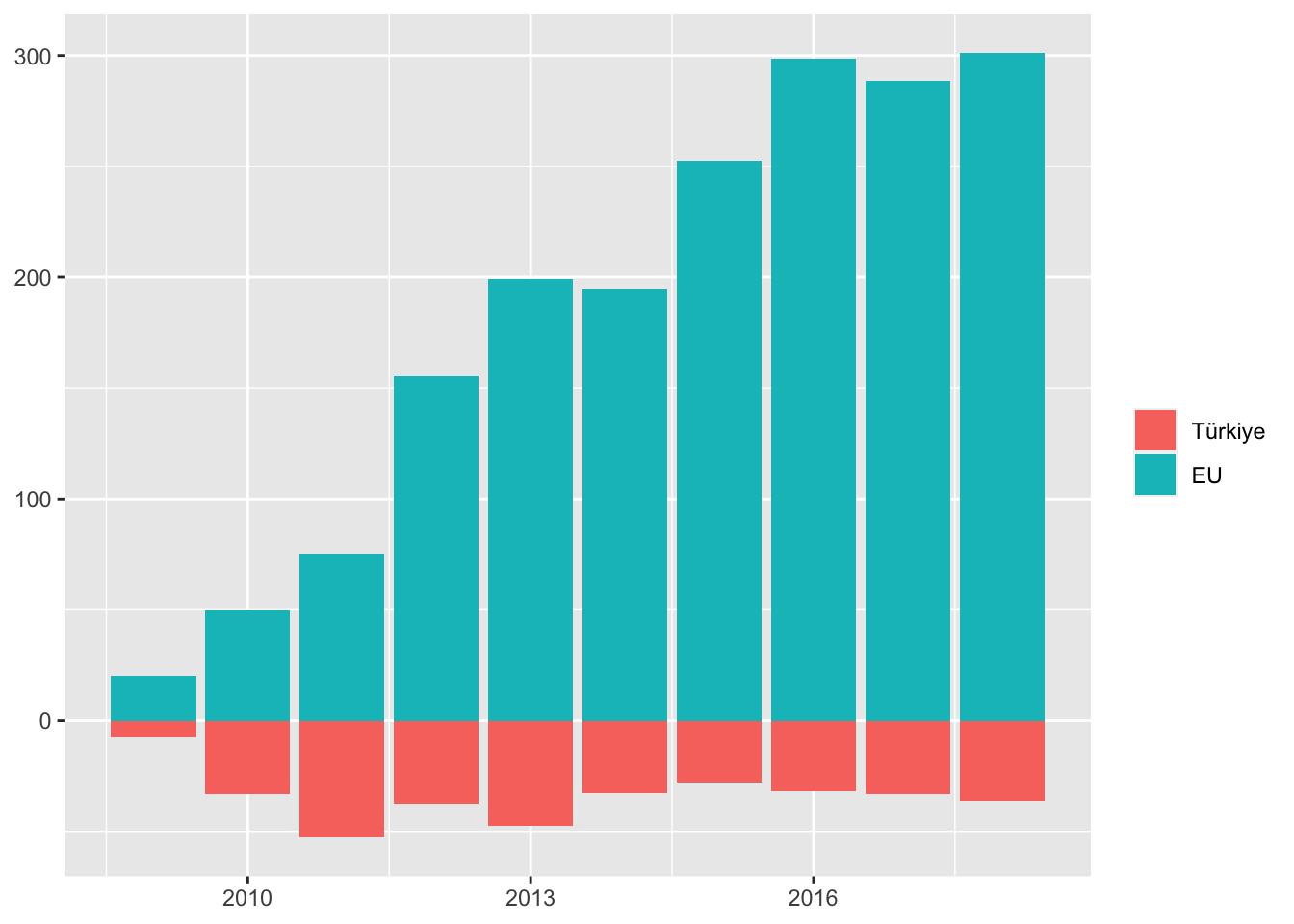 Ülkemiz alacak verecek hesabında borçtan kurtulamazken, AB ülkeleri pozitifte.
Ülkemiz alacak verecek hesabında borçtan kurtulamazken, AB ülkeleri pozitifte.
Yukarıdaki kodları satır satır izah etmedim. Üzerinden giderseniz kolay anlaşılacağını düşünüyorum.
Başlarken belirttiğim gibi, tidyverse büyük verisetlerinin manipülasyonu için kullanışlı araçlar içermekte. Böylelikle kod yazımını önemli ölçüde azaltıyor ve hata yapma ihtimalini de düşürüyor.