R ile metin analizi --kelime sıklıkları ve korelasyon
Önceki yazıdaki kitapta geçen kelimelerin sıklıklarını hesapladık ve örnek olarak iki kelimenin kitapın hangi kısımlarında kullanıldığını gösteren dağılım grafiklerini çizdik. Grafiklerden bazı kelimelerin kitabın belli kısımlarında yoğunlaştığını anladık. Bu yazıda aynı kitabı (Told in the coffee house: Turkish tales) bölümlerine ayırarak, kullanılan kelimelerin frekans değerlerini hesaplayalım ve korelasyon analizi yapalım1. Dolayısıyla öncelikli olarak kitabın bölümlerini belirlememiz gerekiyor. Önceki yazıda yaptığımız gibi kitabın metnini R’a yükleyelim ve dosyada bulunan metadata kısmından kurtulalım.
metin.v <- scan("ttales.txt", what = "character", sep = "\n")
ilk.v <- which(metin.v == "HOW THE HODJA SAVED ALLAH")
son.v <- which(metin.v == "mézé should be immediately served.")
kitap.satir.v <- metin.v[ilk.v:son.v]
kitap.v <- paste(kitap.satir.v, collapse=" ")
kitap.kh.v <- tolower(kitap.v)
kitap.kelimeler.l <- strsplit(kitap.kh.v, "\\W")
kitap.kelimeler.v <- unlist(kitap.kelimeler.l)Kitaba göz attığımızda bölüm başlangıçlarının standart bir şeklinin olmadığını görüyoruz. Günümüzde kitaplarda “Bölüm 1” gibi başlıklarla bölümler ayrılırken, bu kitapta bölümler hikaye isimleriyle ayrılmış. Bu yüzden bölüm başlangıçlarını işaretleyebilmek için kendimize bir içindekiler vektörü oluşturmamız gerekiyor. Bunun çin kitap metnine giderek hikaye isimlerini kopyalayıp c() fonksiyonu yardımıyla kitap.icindekiler.v değişkenini aşağıdaki şekilde oluşturduk. Liste uzun olduğundan tamamını aşağıda göstermedim, .Rmd dosyasında tamamı mevcut:
kitap.icindekiler.v <- c("HOW THE HODJA SAVED ALLAH","BETTER IS THE FOLLY OF WOMAN THAN THE WISDOM OF MAN","THE HANOUM AND THE UNJUST CADI","WHAT HAPPENED TO HADJI, A MERCHANT OF THE BEZESTAN","HOW THE JUNKMAN TRAVELLED TO FIND TREASURE IN HIS OWN YARD","HOW CHAPKIN HALID BECAME CHIEF DETECTIVE","HOW COBBLER AHMET BECAME THE CHIEF ASTROLOGER","THE WISE SON OF ALI PASHA","THE MERCIFUL KHAN","KING KARA-KUSH OF BITHYNIA","THE PRAYER RUG AND THE DISHONEST STEWARD","THE GOOSE, THE EYE, THE DAUGHTER, AND THE ARM","THE FORTY WISE MEN","HOW THE PRIEST KNEW THAT IT WOULD SNOW","WHO WAS THE THIRTEENTH SON","PARADISE SOLD BY THE YARD","JEW TURNED TURK","THE METAMORPHOSIS","THE CALIF OMAR","KALAIDJI AVRAM OF BALATA","HOW MEHMET ALI PASHA OF EGYPT ADMINISTERED JUSTICE","HOW THE FARMER LEARNED TO CURE HIS WIFE--A TURKISH ÆSOP","THE LANGUAGE OF BIRDS","THE SWALLOW'S ADVICE","WE KNOW NOT WHAT THE DAWN MAY BRING FORTH","OLD MEN MADE YOUNG","THE BRIBE","HOW THE DEVIL LOST HIS WAGER","THE EFFECTS OF RAKI")Bölüm başlangıçlarının yerini tespit etmek için grep() fonksiyonunu kullanacağız. Bunu bir while döngüsü ile yapdık. Bilindiği gibi program döngüleri belli bir koşul gerçekleştiği müddetçe belirtilen kodu çalıştıran kontrol elemanlarıdır. İlk satırda bolum.baslari.v isimli bir değişken üreterek değer olarak NA atadık. Sonra döngüde kullanacağımız i parametresine başlangıç değeri olarak “1” atadık. Döngüye koşul olarak içindekiler değişkenimizdeki eleman sayısınca devam etmesini söyledik. Dördüncü satırda grep() ile içindekilerde bulunan bölüm başlıklarını metin içerisinde aradık ve sonucu bolum.baslari.v değişkenine atadık. Her defasında i parametresine “1” ekleyerek döngünün sonlanmasını sağladık. Bu döngüyü ilk denediğimde başlık indekslerinin son 7 tanesi başarısız oldu (NA) çünkü 22. sırada yer alan başlık metinde biraz farklı yazılmış. Metindeki yazımı düzelttikten sonra problem çözüldü. Tabi metni baştan R’a yükleyerek buraya kadarki işlemleri tekrarlamam gerekti.
bolum.baslari.v <- rep("NA",length(kitap.icindekiler.v))
i <- 1
while (i <= length(kitap.icindekiler.v)){
bolum.baslari.v[i] <- grep(kitap.icindekiler.v[i], kitap.satir.v)
i <- i+1
}
bolum.baslari.v## [1] "1" "179" "328" "402" "481" "595" "722" "910" "1018" "1065"
## [11] "1104" "1149" "1217" "1415" "1472" "1663" "1745" "1804" "1916" "1939"
## [21] "1989" "2034" "2098" "2127" "2153" "2184" "2234" "2285" "2325"Böylelikle bölüm başlangıçlarını işaretlemiş olduk. Bölüm başlangıçlarının bir eksiği önceki bölümün sonu olarak kullanılabilir. Ancak son bölüm için bir bölüm sonu işareti eklemekte fayda var. Bunun için kitabın sonuna “END” ibaresini girip, önceki adımda ürettiğimiz indekse bunu da ekleyelim:
kitap.satir.v <- c(kitap.satir.v, "END")
son.v <- length(kitap.satir.v)
bolum.baslari.v <- c(bolum.baslari.v, son.v)
bolum.baslari.v## [1] "1" "179" "328" "402" "481" "595" "722" "910" "1018" "1065"
## [11] "1104" "1149" "1217" "1415" "1472" "1663" "1745" "1804" "1916" "1939"
## [21] "1989" "2034" "2098" "2127" "2153" "2184" "2234" "2285" "2325" "2360"Artık bölümlere göre kelimelerin frekans değerlerini hesaplayabiliriz. Bunu bir for döngüsüyle yapacağız:
i<-1
bolum.raws.l <- list()
bolum.freqs.l <- list()
for(i in 1:length(bolum.baslari.v)){
if(i != length(bolum.baslari.v)){
bolum.basligi <- kitap.satir.v[as.numeric(bolum.baslari.v)[i]]
start <- as.numeric(bolum.baslari.v)[i]+1
end <- as.numeric(bolum.baslari.v)[i+1]-1
bolum.satir.v <- kitap.satir.v[start:end]
bolum.kelime.v <- tolower(paste(bolum.satir.v, collapse=" "))
bolum.kelime.l <- strsplit(bolum.kelime.v, "\\W")
bolum.kelime.v <- unlist(bolum.kelime.l)
bolum.kelime.v <- bolum.kelime.v[which(bolum.kelime.v!="")]
bolum.freqs.t <- table(bolum.kelime.v)
bolum.raws.l[[bolum.basligi]] <- bolum.freqs.t
bolum.freqs.t.rel <- 100*(bolum.freqs.t/sum(bolum.freqs.t))
bolum.freqs.l[[bolum.basligi]] <- bolum.freqs.t.rel
}
}Yukarıdaki kodda öncelikle i parametresini başlatıyoruz ve bölümlerde geçen kelime sayılarını ve frekans değerlerini tutması için liste türü iki değişken üretiyoruz. Döngüde if kısmından sonra;
- Birinci satırda bolum başlıklarını tutan bir değişken oluşturuyoruz,
- 1 ve 3. satırlarda bölümlerin başlangıç ve bitiş satırlarını tespit ediyoruz,
- 4 ile 8. satırlar arasında bir önceki yazıda metnin tamamına yaptığımız şekilde bölümleri noktalama işaretlerinden arındırarak küçük harflerden oluşan kelimelere çeviriyoruz.
- 9 ile 12. satırlarda kelime sayılarını ve herbir kelimenin frekans değerini hesaplıyoruz.
Böylelikle bolum.raws.l bölüm bölüm kelime sayılarını ve bolum.freqs.l bölüm bölüm kelimelerin frekans değerlerini tutuyor. Mesela “rich” ve “poor” kelimelerini bölümlere göre inceleyelim:
rich.l <- cbind(lapply(bolum.freqs.l,'[','rich'))
poor.l <- cbind(lapply(bolum.freqs.l,'[','poor'))
rich.v <- unlist(rich.l)
poor.v <- unlist(poor.l)
poorrich.mx <- as.matrix(cbind(poor.v,rich.v))
colnames(poorrich.mx) <- c("Poor","Rich")
rownames(poorrich.mx) <- rownames(poor.l)
opar <- par(col.axis="dark red", fg="red")
barplot(poorrich.mx, beside = T, ylim = c(0.0,0.8))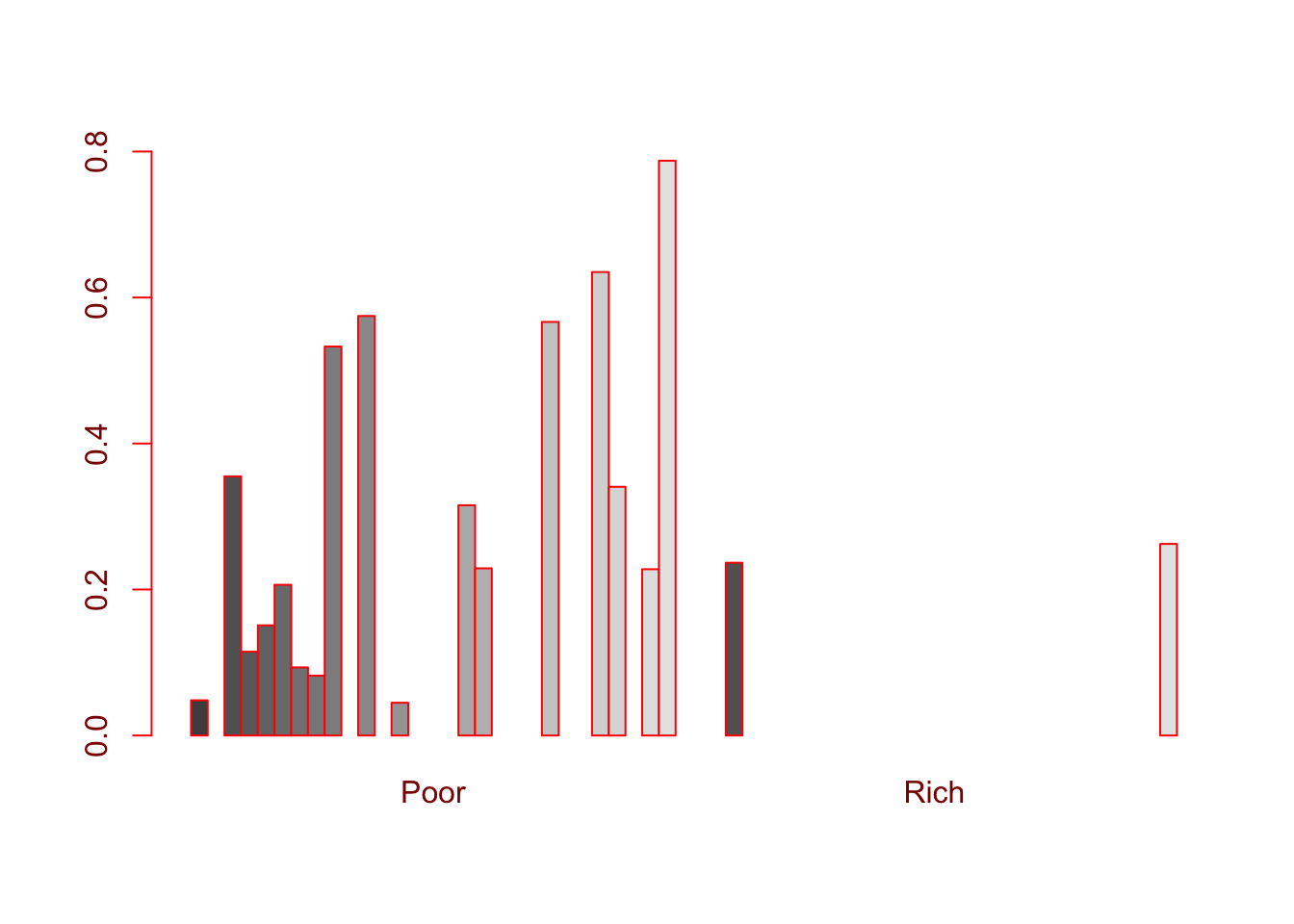
Yukarıda öncelikle “rich”" ve “poor”" kelimelerinden birer liste oluşturduk, sonra bunları vektöre çevrerek poorrich.mx isimli bir matrikste birleştirdik. Matriksin satır ve sütun isimleri düzenlendikten sonra sonucu grafik olarak sunduk. İki grafiği yan yana yerleştirdik. Çubukların koyu renkten açığa gitmesi grafiklerin sınırını belli ediyor. Grafiğe göre hikayeler daha çok fakir insanlarla alakalı. Zengin kelimesi sadece iki hikayede kullanılmış.
Son olarak gözümüze kestirdiğimiz bazı kelimelerin korelasyon değerlerini hesaplayalım. Böylelikle bu kelimelerin bir arada kullanılıp kullanılmadığını görebiliriz. Bunun için yukarıdaki işlemleri tekrarlayarak “hodja”,“hadji”,“pasha”,“wife”,“money” kelimelerinin herbir bölüm için frekans değerlerini tutan yeni bir matriks üreteceğiz:
hodja.l <- lapply(bolum.freqs.l,'[','hodja')
hadji.l <- lapply(bolum.freqs.l,'[','hadji')
pasha.l <- lapply(bolum.freqs.l,'[','pasha')
wife.l <- lapply(bolum.freqs.l,'[','wife')
money.l <- lapply(bolum.freqs.l,'[','money')
hodja.v <- unlist(hodja.l)
hadji.v <- unlist(hadji.l)
pasha.v <- unlist(pasha.l)
wife.v <- unlist(wife.l)
money.v <- unlist(money.l)
hodjagold.mx <- as.matrix(cbind(hodja.v,hadji.v,pasha.v,wife.v,money.v))
rownames(hodjagold.mx) <- rownames(poor.l)
colnames(hodjagold.mx) <- c("Hodja","Hadji","Pasha","Wife","Money")İkinci adımda matriksteki NA değerleri yerine “0” rakamını atayıp korelasyon değerlerini hesapladık:
hodjagold.mx[which(is.na(hodjagold.mx))] <- 0
cor(hodjagold.mx)## Hodja Hadji Pasha Wife Money
## Hodja 1.00000000 -0.09627886 -0.01223343 -0.1348489 -0.17565310
## Hadji -0.09627886 1.00000000 -0.13389725 0.6927323 -0.06640128
## Pasha -0.01223343 -0.13389725 1.00000000 -0.1018197 0.36553969
## Wife -0.13484886 0.69273227 -0.10181972 1.0000000 -0.24741774
## Money -0.17565310 -0.06640128 0.36553969 -0.2474177 1.00000000Görüldüğü gibi en güçlü pozitif korrelasyon 0,69 ile “Hadji” ve “Wife” kelimeleri arasında. Sonraki en güçlü pozitif korrelasyon 0,37 ile “Pasha” ve “Money” kelimeleri arasında. Yani bu kelimelerden birisinin metinde bulunmasi, diğerinin de bulunma olasılığını arttırıyor.
En güçlü negatif korrelasyon 0,25 ile “Wife” ve “Money” kelimeleri arasında. Sonraki en güçlü negatif korrelasyon 1,75 ile “Hodja” ve “Money” kelimeleri arasında. Yani bu kelimelerin birisinin bulunması halinde diğerinin bulunma olasılığı daha az.
Peki bunlar ne anlama geliyor dersek, tek başına bu kadar bilgiyle yorum yapmak hatalı olur. Belki şu tahminler yürütülebilir; hikayelerde hacı diye anılan kişi veya kişilerin aynı zamanda eşlerinden de bahsediliyor olabilir. Diğer yandan hikayelerde geçen paşaların zengin veya parayla ilgili oldukları, ancak hocaların ve eşlerin parayla çok ilgili olmadıkları düşünülebilir.