R ile metin analizi --Kelime çeşitliliği
Bu yazıda içerik analizine devam ederek ilk iki yazıda üzerinde çalıştığımız kitabımızı bu sefer de kelime zenginliği açısından ele alacağız. Kelime zenginliğini ölçmek için iki farklı ölçeğe bakacağız. Bunlar her ne kadar tartışmalı ölçekler olsa da yine de metin hakkında bize fikir verebilirler.1
Analiz için önceki yazıda ürettiğimiz, bölümlerde geçen kelime sayılarını tutan bolum.raws.l ismini verdiğimiz liste türü değişkene ihtiyacımız olacak. Bu değikenleri elde ettiğimiz aynı işlemleri burada tekrarlamayacağım. Önceki yazıda yahut .Rmd dosyasında ilgili kodu bulabilirsiniz.
metin.v <- scan("ttales.txt", what = "character", sep = "\n")
ilk.v <- which(metin.v == "HOW THE HODJA SAVED ALLAH")
son.v <- which(metin.v == "mézé should be immediately served.")
kitap.satir.v <- metin.v[ilk.v:son.v]
kitap.v <- paste(kitap.satir.v, collapse=" ")
kitap.kh.v <- tolower(kitap.v)
kitap.kelimeler.l <- strsplit(kitap.kh.v, "\\W")
kitap.kelimeler.v <- unlist(kitap.kelimeler.l)
kitap.icindekiler.v <- c("HOW THE HODJA SAVED ALLAH","BETTER IS THE FOLLY OF WOMAN THAN THE WISDOM OF MAN","THE HANOUM AND THE UNJUST CADI","WHAT HAPPENED TO HADJI, A MERCHANT OF THE BEZESTAN","HOW THE JUNKMAN TRAVELLED TO FIND TREASURE IN HIS OWN YARD","HOW CHAPKIN HALID BECAME CHIEF DETECTIVE","HOW COBBLER AHMET BECAME THE CHIEF ASTROLOGER","THE WISE SON OF ALI PASHA","THE MERCIFUL KHAN","KING KARA-KUSH OF BITHYNIA","THE PRAYER RUG AND THE DISHONEST STEWARD","THE GOOSE, THE EYE, THE DAUGHTER, AND THE ARM","THE FORTY WISE MEN","HOW THE PRIEST KNEW THAT IT WOULD SNOW","WHO WAS THE THIRTEENTH SON","PARADISE SOLD BY THE YARD","JEW TURNED TURK","THE METAMORPHOSIS","THE CALIF OMAR","KALAIDJI AVRAM OF BALATA","HOW MEHMET ALI PASHA OF EGYPT ADMINISTERED JUSTICE","HOW THE FARMER LEARNED TO CURE HIS WIFE--A TURKISH ÆSOP","THE LANGUAGE OF BIRDS","THE SWALLOW'S ADVICE","WE KNOW NOT WHAT THE DAWN MAY BRING FORTH","OLD MEN MADE YOUNG","THE BRIBE","HOW THE DEVIL LOST HIS WAGER","THE EFFECTS OF RAKI")
bolum.baslari.v <- rep("NA",length(kitap.icindekiler.v))
i <- 1
while (i <= length(kitap.icindekiler.v)){
bolum.baslari.v[i] <- grep(kitap.icindekiler.v[i], kitap.satir.v)
i <- i+1
}
kitap.satir.v <- c(kitap.satir.v, "END")
son.v <- length(kitap.satir.v)
bolum.baslari.v <- c(bolum.baslari.v, son.v)
i<-1
bolum.raws.l <- list()
bolum.freqs.l <- list()
for(i in 1:length(bolum.baslari.v)){
if(i != length(bolum.baslari.v)){
bolum.basligi <- kitap.satir.v[as.numeric(bolum.baslari.v)[i]]
start <- as.numeric(bolum.baslari.v)[i]+1
end <- as.numeric(bolum.baslari.v)[i+1]-1
bolum.satir.v <- kitap.satir.v[start:end]
bolum.kelime.v <- tolower(paste(bolum.satir.v, collapse=" "))
bolum.kelime.l <- strsplit(bolum.kelime.v, "\\W")
bolum.kelime.v <- unlist(bolum.kelime.l)
bolum.kelime.v <- bolum.kelime.v[which(bolum.kelime.v!="")]
bolum.freqs.t <- table(bolum.kelime.v)
bolum.raws.l[[bolum.basligi]] <- bolum.freqs.t
bolum.freqs.t.rel <- 100*(bolum.freqs.t/sum(bolum.freqs.t))
bolum.freqs.l[[bolum.basligi]] <- bolum.freqs.t.rel
}
}Metnin kelime zenginliği edebi kalitesini gösterdiği gibi okuyucular tarafından kolay anlaşılır olmasını da belirlemektedir. Genellikle fazla sayıda farklı kelime içeren metinlerin anlaşılması daha güç olur ve yavaş okunur. Metnin kelime zenginliğini gösteren ölçeklerden birisi, herbir kelimenin ortalama ne kadar kullanıldığının hesaplanması. Bunun için lapply() veya sapply() fonksiyonlarını kullanabiliriz. Bu iki fonksiyon da aynı biçimde çalışmaktadır, tek farkları ilkinin çıktısı liste türü, ikincisinin ise vektör türü olacaktır.
Aşağıdaki kodda do.call() fonksiyonunu kullandım. do.call() başka fonksiyonları girdi olarak kabul ederek işlem yapan bir fonksiyondur. Burada lapply() ile ortalamalar hesaplanıyor ve rbind() ile birlikte do.call() fonksiyonuna girdi olarak matriks türü bir veriye çevriliyor. Ardından elde ettiğimiz ortalamalara ait iki grafik çiziyoruz. İlkinde ortalamaların ham halini, ikincisinde scale() fonksiyonuyla normalize edilmiş halini çizdim. scale() fonksiyonu bölüm ortalamalarını, kitap ortalamasından çıkartıyor. Grafikteki “0” noktası ortalamayı gösteriyor. Eksi değerler ortalamanın altındaki, artı değerler üzerindeki bölümleri ifade ediyor:
ort.kelime.freq.m <- do.call(rbind, lapply(bolum.raws.l,mean))
plot(ort.kelime.freq.m, type = "h")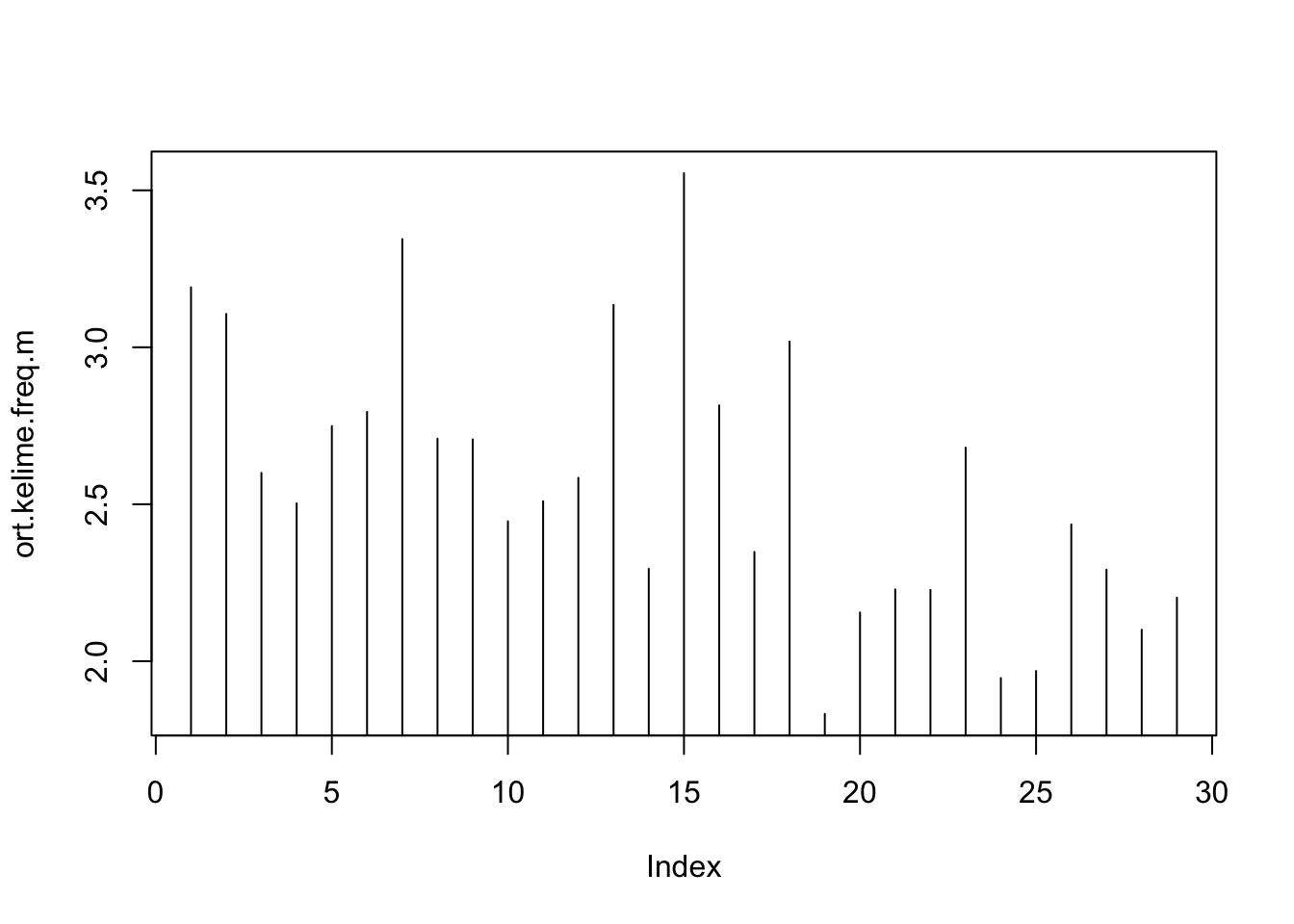
plot(scale(ort.kelime.freq.m), type = "h")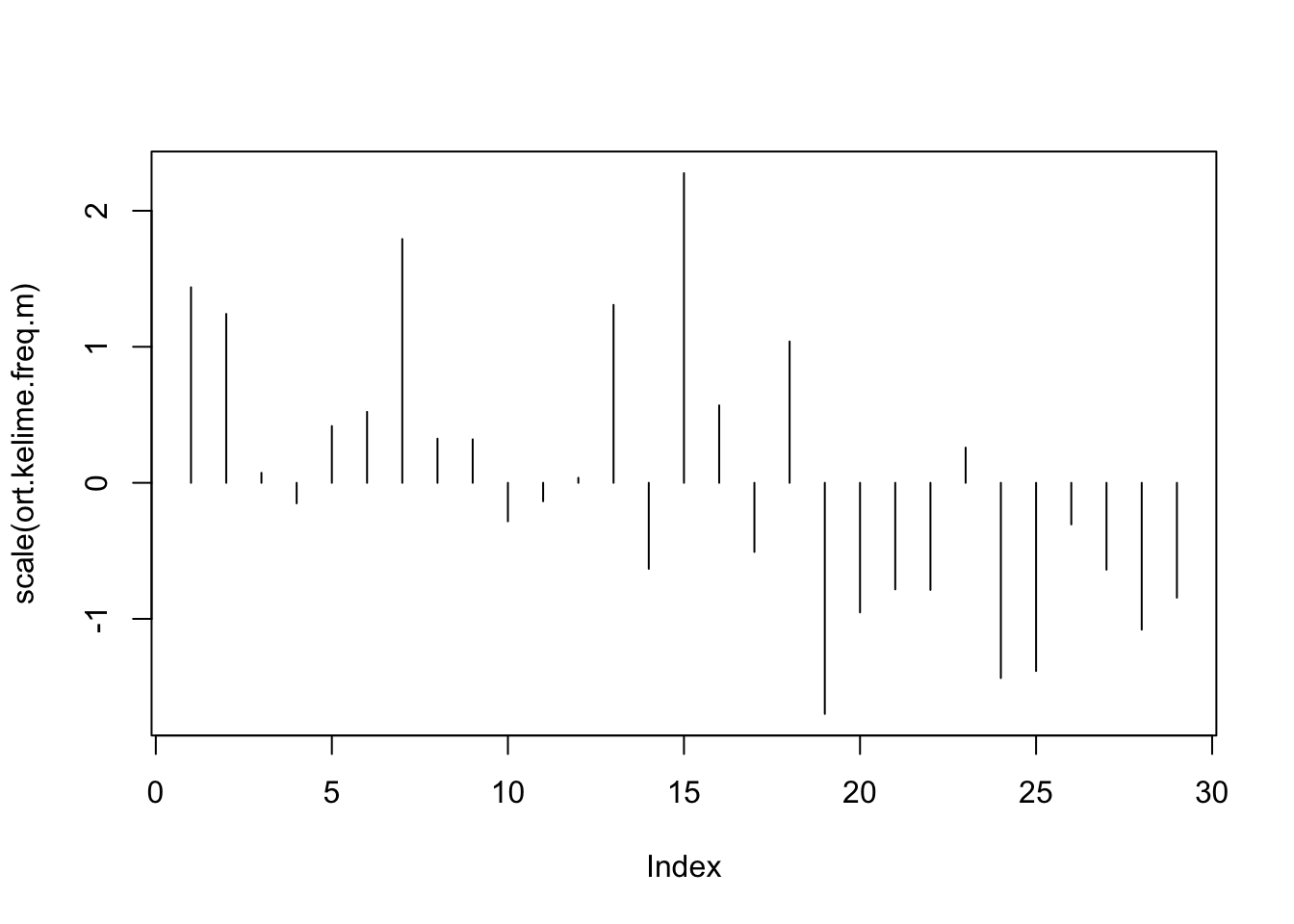
Ortalama kelime sayısı kelime zenginliğinin ölçeklerinden olmasına rağmen, bölüm uzunluğu arttıkça farklı kelime kullanma ihtimali haliyle azalacağından dikkatli kullanılması gereken bir ölçektir. Bu durumu kontrol etmek için bölümlerin içerdiği toplam kelime sayılarıyla ortalama kelime sayısı değişkenimizin korelasyon değerini hesaplayabiliriz. Bunun için öncelikle bölümlerde kullanılan toplam kelime sayılarını hesapladık sonrada analizi yaptık:
bolum.kelime.m <- do.call(rbind, lapply(bolum.raws.l, sum))
cor(bolum.kelime.m[,1], ort.kelime.freq.m[,1])## [1] 0.8958854Görüldüğü üzere yüksek pozitif korrelasyon var. Yani metindeki kelime sayısı arttıkça, aynı kelimelerin kullanılma oranı da artıyor, diğer bir deyişle kelime zenginliği azalıyor.
Metnin kelime zenginliğini ölçmenin diğer bir yolu, hapax olarak adlandırılan, sadece bir kere kullanılan kelimelerin tespit edilmesi yöntemidir. Bunun için ev yapımı bir fonksiyon kullanacağız:
bolum.hapax.v <- sapply(bolum.raws.l, function(x) sum(x == 1))Burada sapply()içerisinde küçük bir fonksiyon tanımlıyoruz ve sapply() ile bölümlerde kullanılan kelime sayılarını bu fonksiyona girdi yapıyoruz. Böylelikle bolum.raws.l listesinde sadece bir kere kullanılmış olan kelimelerin sayısını hesaplayarak bolum.hapax.v vektörüne kaydediyoruz.
Tek başına bu veri fazla anlam taşımadığından, bölümleri birbirleriyle karşılaştırabilmek için her bölüm için hapax değerinin toplam kelime sayısına oranını hesaplayıp grafik haline getirelim:
hapax.oran <- bolum.hapax.v / bolum.kelime.m
barplot(hapax.oran, space=1, beside=T,col="grey",
names.arg = seq(1:length(bolum.raws.l)))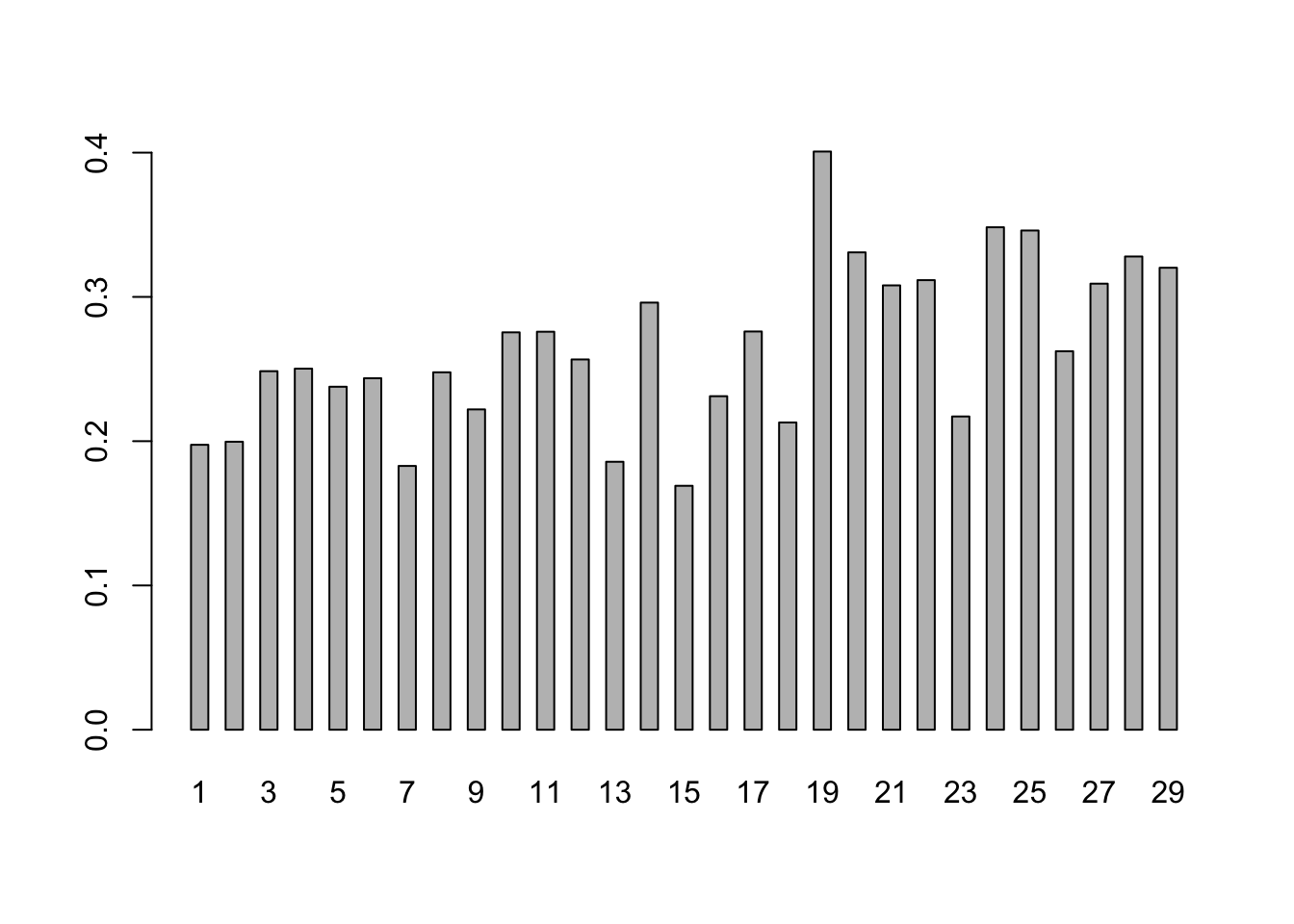
Yukarıda çizdiğimiz kelime ortalamalarını gösteren grafiğe yakın bir grafik elde ettik. Hapax değerlerinin de bölümlerde kullanılan kelime sayılarıyla korelasyonuna bakmakta fayda var:
cor(hapax.oran, ort.kelime.freq.m[,1])## [,1]
## [1,] -0.9619583Görüldüğü gibi çok güçlü negatif bir korelasyon var. Dolayısıyla bölümlerin toplam farklı kelime sayısı arttıkça, bir defa kullanılan kelime sayısının azaldığını görüyoruz. Daha fazla bilgi için bu yazıda faydalandığım Matthew J. Jockers’ın Text Analysis with R for Students of Literature adlı kitabına başvurulabilir.