R ile metin analizi
Bu yazıda R ile metin analizi yapmaya çalışacağız. Bunun için öncelikle Project Gutenberg sitesinden uygun bir .txt dosyası indirdim. Aslında Türkçe bir metin olsa daha faydalı olurdu ancak yeterli büyüklükte Türkçe bir metin bulmanın zorluğundan dolayı, 1898 tarihli Told in the coffee house: Turkish tales başlıklı, Türkiyeyle alakalı bir kitap üzerinde çalışalım diye düşündüm. Bu kitabı daha önce okumadım. Bakalım yapacağımız analizler kitap hakkında bize nasıl bir fikir verecek. Buradaki analizleri Matthew J. Jockers’ın Text Analysis with R for Students of Literature adlı kitabından kısmen değiştirerek aldım.
Öncelikle metni R’a aktarmamız gerekiyor. Metni metin.v adını verdiğimiz bir vektöre aktaralım ve vektörün ilk veri nesnesini sorgulayalım. Aşağıdaki kodda yer alan sep= "n" ibaresi herbir satırın vektörümüzde ayrı bir veri nesnesi olmasını sağlıyor:
metin.v <- scan("ttales.txt", what = "character", sep = "\n")
metin.v[1]## [1] "Project Gutenberg's Told in the Coffee House, by Cyrus Adler and Allan Ramsay"Görüldüğü üzere metin.v vektörümüzde toplam 2830 veri nesnesi veya satır var ve ilk veri nesnesi kitabın ve yazarlarının adı. Project Gutenberg’de yer alan kitabların başında ve sonuda kitaba ilişkin metadata bulunduğundan doğru bir analiz için kitabın başlangıç ve bitiş satırlarını işaretlememiz gerekiyor. Bunun için metne bakarak ilk ve son satırları tespit edip R ile işaretledik. Aşağıda görüleceği gibi kitap 96. satırda başlayıp, 2454. satırda bitiyor Son olarak metadatasız sadece kitap metninden müteşekkil, 2359 veri nesnesi veya satır içeren yeni bir vektör üretiyoruz:
ilk.v <- which(metin.v == "HOW THE HODJA SAVED ALLAH")
son.v <- which(metin.v == "mézé should be immediately served.")
ilk.v; son.v## [1] 96## [1] 2454length(kitap.satir.v <- metin.v[ilk.v:son.v])## [1] 2359Veri üzerinde analize başlamadan önce yapmamız gereken son işlem kitapta yer alan herbir kelimenin ayrı ayrı birer nesne olduğu bir kelime vektörü oluşturmak. Bunun için öncelikle elimizdeki metni satırlardan oluşan bir vektör olmaktan çıkartacağız. Aşağıdaki kodda öncelikle paste() fonksiyonuyla kitap.satir.v değişkeninde yer alan nesneleri aralarına boşluk yerleştirerek (collapse=" ") birleştirdik ve tek bir veri nesnesinden oluşan bir vektör elde ettik. İkinci olarak kitaptaki harflerin tamamını küçük harfe çevirdik:
kitap.v <- paste(kitap.satir.v, collapse=" ")
kitap.kh.v <- tolower(kitap.v)
kitap.kelimeler.l <- strsplit(kitap.kh.v, "\\W")
kitap.kelimeler.v <- unlist(kitap.kelimeler.l)Üçüncü adımda strsplit() fonksiyonuyla noktalama işaretlerinden kurtulduk. strsplit() fonksiyonu ilk parametre olarak küçük harflerden oluşan vektörümüzü, ikinci olarak kurtulmak istediğimiz karakteri aldı. \W regular expression olarak adlandırılan ve belli ibareleri ifade etmeye yarayan karakterlerdir. Buradaki karakter kelime olmayan herşeyi ifade etmektedir. strsplit() fonksiyonunun çıktısı liste olduğundan yeni değişkenimizi kitap.kelimeler.l olarak adlandırdık. Lakin bize lazim olan vektör türü veri olduğundan son adımda eldeki listeyi tekrar vektöre çevirdik. Şimdi ürettiğimiz kelime vektörüne bir göz atalım:
kitap.kelimeler.v[1:50]## [1] "how" "the" "hodja" "saved" "allah"
## [6] "not" "far" "from" "the" "famous"
## [11] "mosque" "bayezid" "an" "old" "hodja"
## [16] "kept" "a" "school" "" "and"
## [21] "very" "skilfully" "he" "taught" "the"
## [26] "rising" "generation" "the" "everlasting" "lesson"
## [31] "from" "the" "book" "of" "books"
## [36] "" "such" "knowledge" "had" "he"
## [41] "of" "human" "nature" "that" "by"
## [46] "a" "glance" "at" "his" "pupil"Çıktıya baktığımızda 19 ve 36. karakterlerin boş olduğunu görüyoruz. Bunlar yukarıda kendilerinden kurtulduğumuz noktalama işaretleri. strsplit() fonksiyonu kelime dışındaki herşeyi ortadan kaldırdı ancak onların yerini boşluk olarak bıraktı. Bunlardan da kurtulmak için önce which() fonksiyonuyla kitap.kelimeler.v vektöründeki kelimelerin indeks bilgilerini tutan bosluk.degil.v vektörünü oluşturduk. İkinci satırda ilk bu vektördeki ilk 20 indeks değerine baktığımızda 19 numaralı indeksin olmadığını yani burada bir kelime olmadığını görüyoruz. Son satırdaysa önceki aşamada ürettiğimiz kitap.kelimeler.v vektörünü boşluklardan kurtarıyoruz. İlk 50 kelimeye tekrar bakarsak boşlukların gittiğini görürüz:
bosluk.degil.v <- which(kitap.kelimeler.v != "")
kitap.kelimeler.v <- kitap.kelimeler.v[bosluk.degil.v]Kitap metnini incelenebilir bir hale getirdiğimize göre artık analize başlayabiliriz. Öncelikle kitapın 26.852 kelimeden ibaret olduğunu ve bunun da 3.575 farklı kelime içerdiğini görüyoruz.
length(kitap.kelimeler.v)## [1] 26852length(unique(kitap.kelimeler.v))## [1] 3575Sonra en sık kullanılan kelimelere bakalım. Öncelikle table() fonksiyonunu kullanarak kitap.kelimeler.v vektöründe yer alan kelimelerin frekans değerlerini bulduk. İkinci aşamada bu değerleri büyükten küçüğe sıraladık ve son olarak en çok kullanılan 100 kelimeyi listeledik:
kitap.freqs.t <- table(kitap.kelimeler.v)
kitap.freqs.t <- sort(kitap.freqs.t, decreasing = TRUE)
kitap.freqs.t[1:100]## kitap.kelimeler.v
## the and to of he his a that
## 2220 1039 938 754 573 527 522 413
## in was had i it you for him
## 409 372 258 244 229 226 216 207
## as at not this with be on but
## 166 163 162 162 154 144 143 141
## one is said have would man my s
## 137 136 128 121 111 108 106 105
## so will by your were what no from
## 97 95 93 92 90 89 82 79
## been her when ahmet if who an pasha
## 78 78 78 77 77 77 75 72
## they them me all out jew then day
## 72 71 70 68 63 62 62 61
## their which wife now there do hodja or
## 61 61 60 58 56 54 51 51
## asked into time did father see went came
## 50 50 50 49 48 48 48 47
## hadji she told after are come great money
## 47 47 47 46 46 45 45 45
## dervish go could men much cadi eye old
## 44 44 43 42 42 41 41 40
## put again give piasters poor up very long
## 40 39 38 38 37 37 37 36
## thou has allah brought
## 36 35 34 34Listenin en başında İngilizce gramerine has kelimeler ve zamirler görüyoruz. Zamirler içerisinde erkekleri ifade eden he ve his 573 ve 527 defa kullanılırken, kadınları ifade eden she ve her kelimeleri 47 ve 78 defa kullanılmış. Aşağıda görüldüğü gibi he zamiri she zamirine göre 12 kat daha fazla kullanılmış:
kitap.freqs.t["he"] / kitap.freqs.t["she"]## he
## 12.19149Dolayısıyla kitapta yer alan hikayelerin daha çok erkeklerle ilgili olduğunu anlıyoruz. Metinde 60 defa geçen wife kelimesi kadınlardan daha çok eş olarak bahsedildiği fikrini veriyor. Dini anlam ifade eden kelimeler; hodja 70, hadji 47, dervish 44 ve Allah 34 defa metinde geçmiş. İlginçtir ki Yahudi anlamına gelen Jew kelimesi metinde 62 defa geçmiş. Dolayısıyla hikayelerde o dönemlerde içiçe yaşadığımız Yahudilerle ilgili konuların da olduğu anlaşılıyor.
Son olarak herhangi bir kelimenin kitap boyunca dağılımını grafik olarak görelim. Bunun için öncelikle kitapta geçen kelime sayısınca indeks değer içeren bir vektör oluşturalım. İkinci olarak incelemek istediğimiz bir kelimenin mesela Jew kelimesinin indeks numaralarını tutan ikinci bir değişken oluşturalım. Üçüncü satırda kitaptaki kelime sayısınca NA değeri olan bir değişken oluşturduk ve dördüncü Jew kelimesinin indeks değerlerine “1” değerini atadık ve son olarak graği oluşturduk. Aynı incelemeyi hodja kelimesi için de yaptık ve iki grafiği alt alta ürettik:
indeks.v <- seq(1:length(kitap.kelimeler.v))
jew.v <- which(kitap.kelimeler.v == "jew")
j.sayi.v <- rep(NA,length(indeks.v))
j.sayi.v [jew.v] <- 1
par(mfrow=c(2,1))
plot(j.sayi.v, main="'Jew' kelimesine ait dağılım grafiği",
xlab="Kitaptaki yeri", ylab="Jew", type="h", ylim=c(0,1), yaxt='n')
indeks.v <- seq(1:length(kitap.kelimeler.v))
hodja.v <- which(kitap.kelimeler.v == "hodja")
h.sayi.v <- rep(NA,length(indeks.v))
h.sayi.v [hodja.v] <- 1
plot(h.sayi.v, main="'Hodja' kelimesine ait dağılım grafiği",
xlab="Kitaptaki yeri", ylab="Hodja", type="h", ylim=c(0,1), yaxt='n')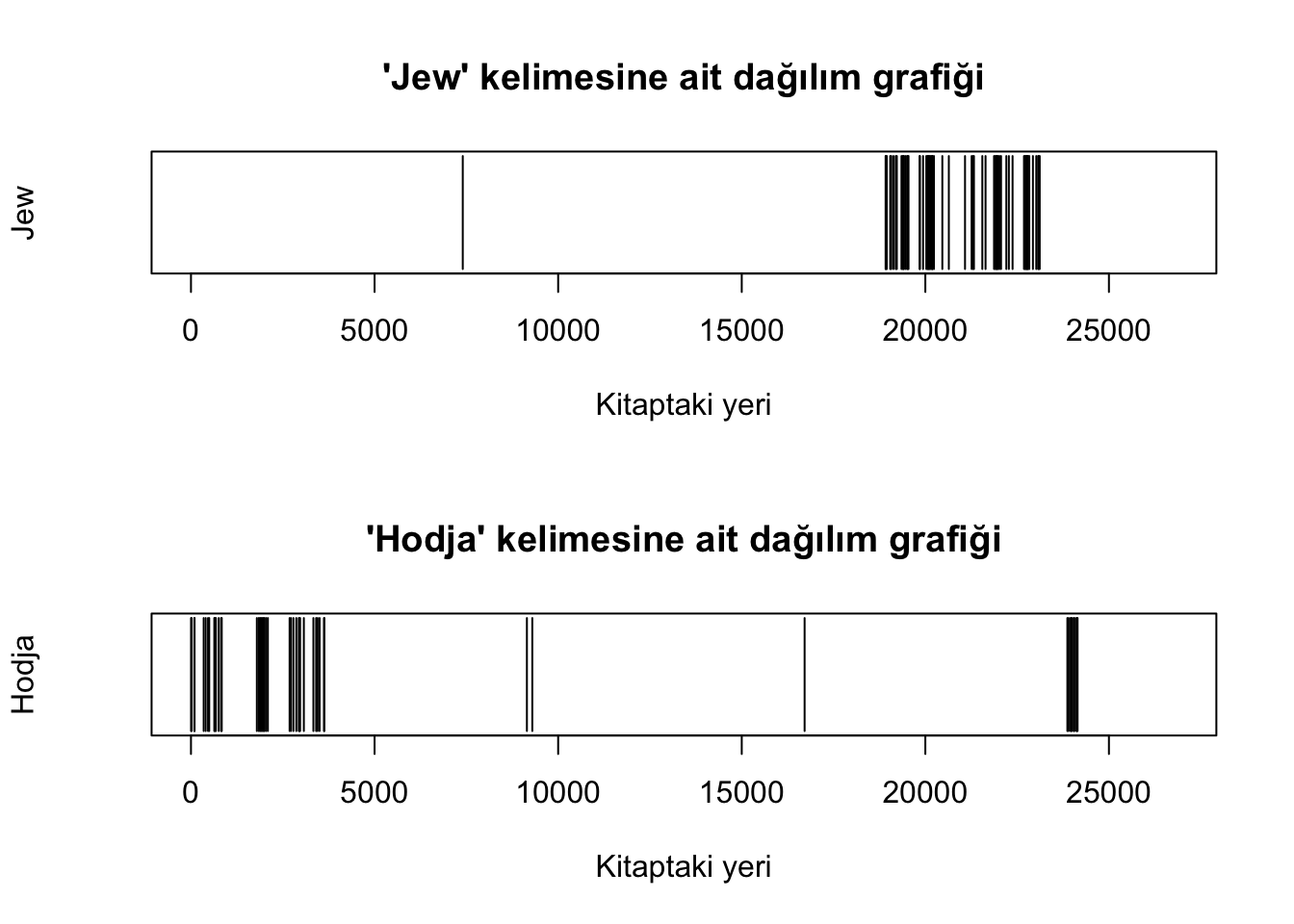
Yukarıdaki grafikte de görüldüğü gibi Jew kelimesi yoğun olarak kitabın son kısmında kullanılmış. Buna karşın hodja kelimesi ağırlıkla başlarda kullanılmış. Dolayısıyla kitapta isimleri yerine “Yahudi” ve “Hoca” şeklinde anılan kişilerden bahsedildiğini anlıyoruz. Diğer kelimelerin de dağılım grafiklerini üreterek belli bir hikayeye has mı yoksa kitabın genelinde mi kullanıldığını görebiliriz.