Olasılık Hesapları ve İstitistiksel Dağılımlar
İstatistiksel hesaplamaların pek çoğu verinin rastgele dağılıma sahip olduğu varsayımına dayanır. Ancak gerçek hayatta, özellikle sosyal bilimlerde rastgele dağılıma sahip veri bulabilmek güçtür. İstatistiksel paketler rastgele dağılıma yakın veri üretmemize imkan verir. R ile rastgele dağılıma sahip bir set üretmek içiin sample() fonksiyonu kullanılabilir.
sample(0:100, 10)## [1] 52 67 38 12 59 47 62 89 20 42sample() fonksiyonuna giren ilk değer rastgele üretilecek sayı aralığını ifade eden vektör, ikincisi ise kaç sayı üretileceğini ifade eden değerdir. Yukarıdaki örnekte aynı sayının birden fazla örneklemde bulunması engellenmiştir. Bazı durumlarda aynı değerin birden fazla bulunabilmesi gerekebilir. Mesela, yazı-tura sonuçlarına ilişkin bir rastgele dizide iki değer olmalıdır:
sample(c("Y","T"), 10, replace = T)## [1] "Y" "T" "T" "T" "Y" "Y" "Y" "Y" "T" "Y"Burada replace=T ile aynı değerin tekrar etmesini sağlıyoruz. Buna ilaveten sample() fonksiyonunda dizide bulunacak değerlerin ihtimallerini de belirleyebiliz. Mesela yazı tura attığımız parada bir dengesizlik var ve yazı gelme ihtimali 0.8 ve tura gelme ihtimali 0.2 ise;
sample(c("Y","T"), 10, prob = c(.8,.2), replace = T)## [1] "T" "T" "Y" "Y" "Y" "Y" "Y" "Y" "Y" "Y"Yahut 10 kişilik örneklem alacağımız bir grupta erkeklerin oranı 0.65, kadınların oranı 0.35 ise ve buna uygun bir örneklem almak istiyorsak;
sample(c("E","K"), 10, prob = c(.65,.35), replace = T)## [1] "E" "E" "E" "E" "E" "E" "E" "E" "E" "E"Olasılık Hesapları ve Kombinasyon
sample() fonksiyonuna ilişkin yukarıda verdiğimiz ilk örneğe (sample(0:100, 10)) geri dönelim.Aynı sayının birden fazla defa çıkma ihtimali olmadığından herhangi bir sayının ilk olma ihtimali 1/100, ikinci olma ihtimali 1/99, üçüncü olma ihtimali 1/98 şeklinde devam etmektedir. Bu durumda elde edeceğimiz örneklem 1/(100 x 99 x 98 x … x 90) olasılığa sahiptir. R ile bunu hesaplamak için prod() fonksiyonunu kullanabiliriz:
1/prod(100:91)## [1] 1.59196e-20Bu örnekte örneklemdeki değerlerin sıralamasını önemsemedik. Şayet sıralamayı da göz önüne almamız gerekiyorsa ihtimal hesabını aşağıdaki gibi yapabiliriz;
prod(10:1)/prod(100:91)## [1] 5.776904e-14R ile istatistiksel dağılımlara ilişkin 1) yoğunluk (density), 2) birikimli olasılık dağılım fonksiyonu (cumulated probability distribution function), 3) quantile ve 4) rastgele sayı (pseudo-random numbers) hesaplamaları yapılabilir. Şimdi kısaca bunlara bakalım.
Yoğunluk (density)
Sürekli dağılımlar için yoğunluk, x değerine yakın bir değer elde etme olasılığı olarak ifade edilebilir. Belli bir aralıkta bir değer elde etme ihtimali eğrinin o aralığın altında kalan kısmıdır. Kesikli (discrete) dağılımlar için yoğunluk tam olarak xdeğerini elde etme ihtimalidir. Normal dağılıma ait yoğunluk fonksiyonu dnorm() ile hesaplanabilir. Mesela dnorm() fonksiyonunu çan eğrisi şeklindeki normal dağılım eğrisini elde etmek için kullanabiliriz:
x <- seq(-4,4,.1)
plot(x, dnorm(x), type="l")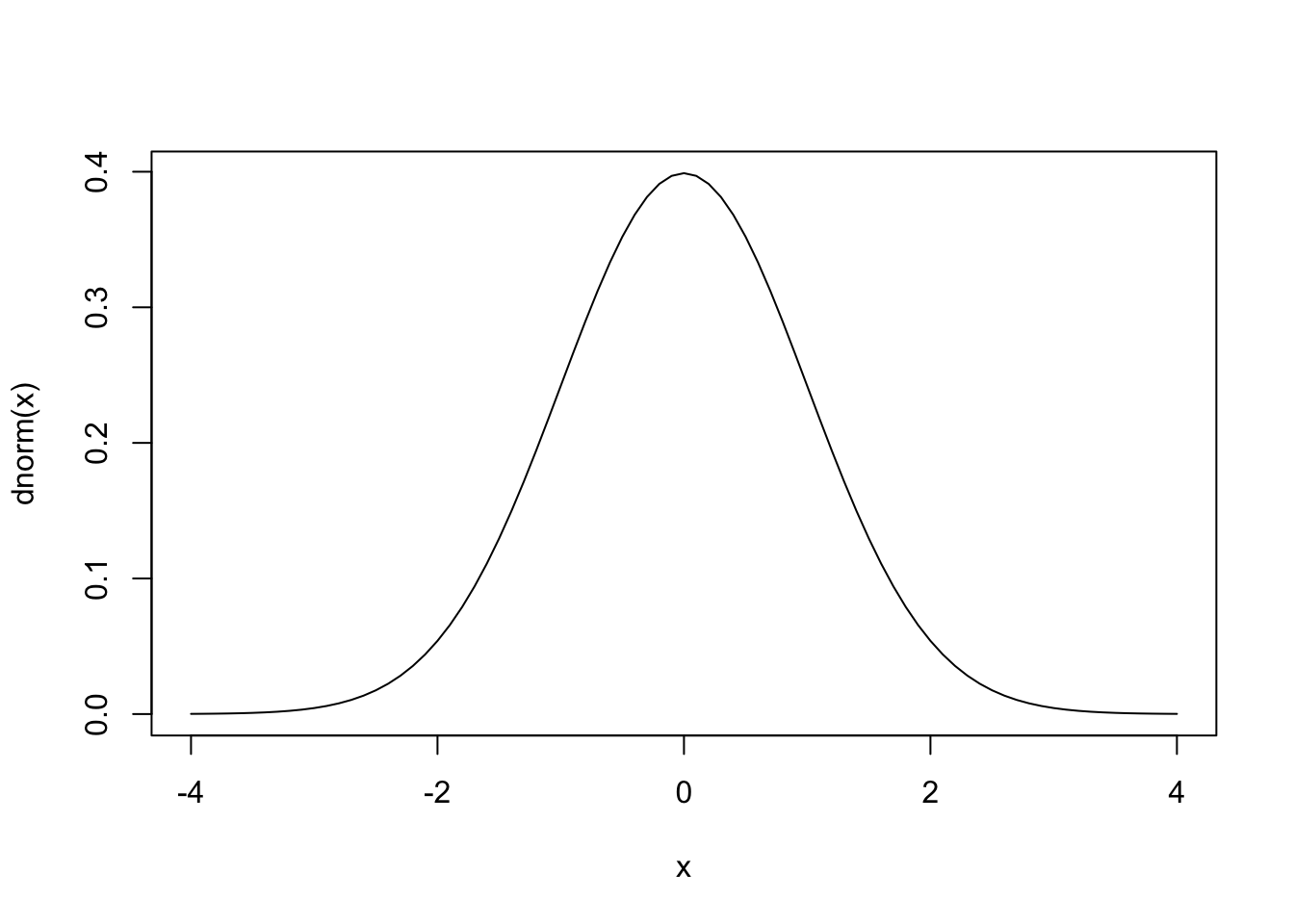
plot() fonksiyonunda kullandığımız type=l (küçük L harfi) çizgi şeklinde bir grafik elde etmemizi sağlar. Aynı grafiği curve() fonksiyonu kullanarak ta çizebiliriz:
curve(dnorm(x), from=-4, to=4)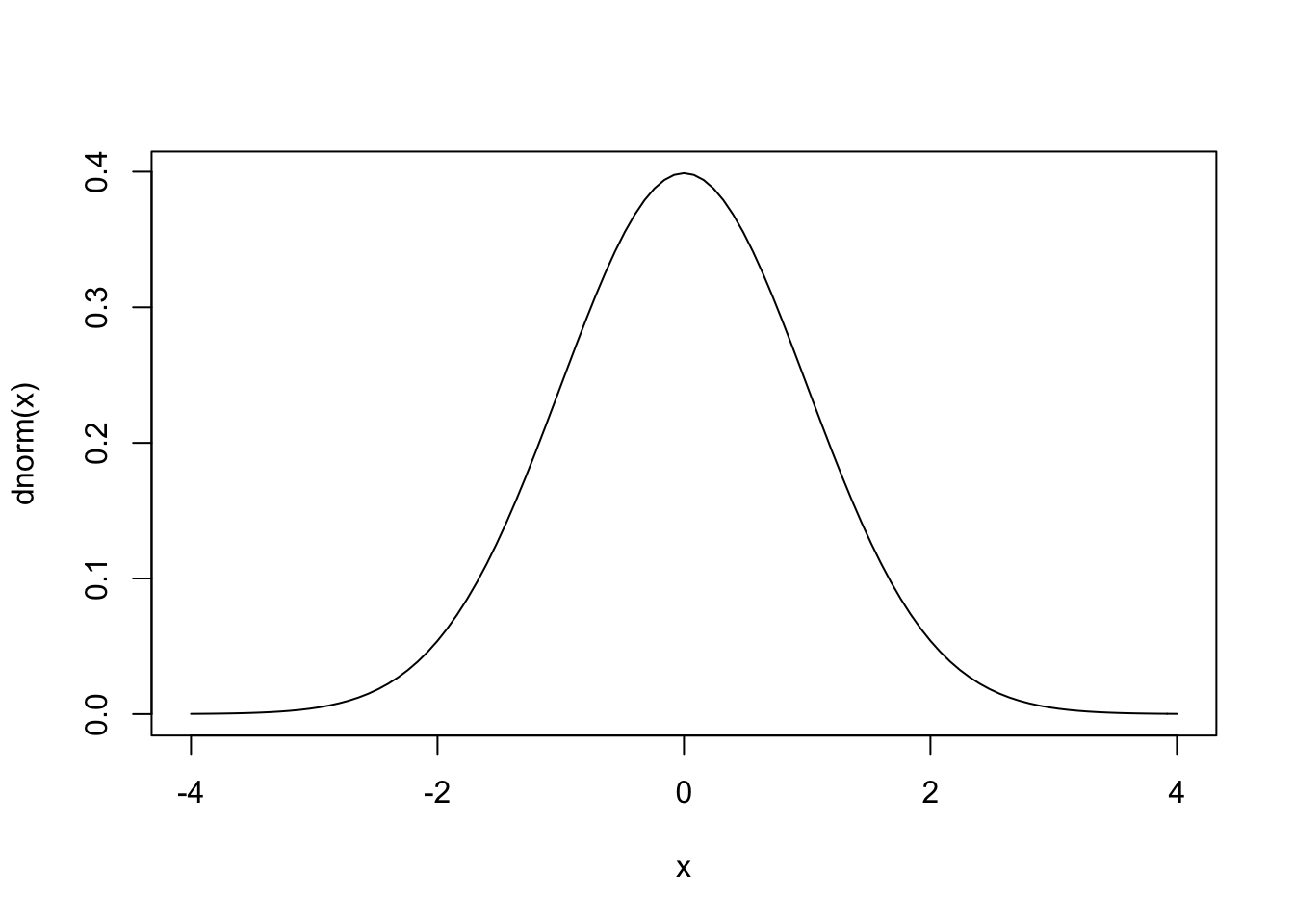
Kesikli dağılımlardan olan binomyal dağılım için yoğunluk, dbinom() ile hesaplanabilir.:
x <- 0:50
plot(x, dbinom(x, size = 50, prob = .33),type = "h")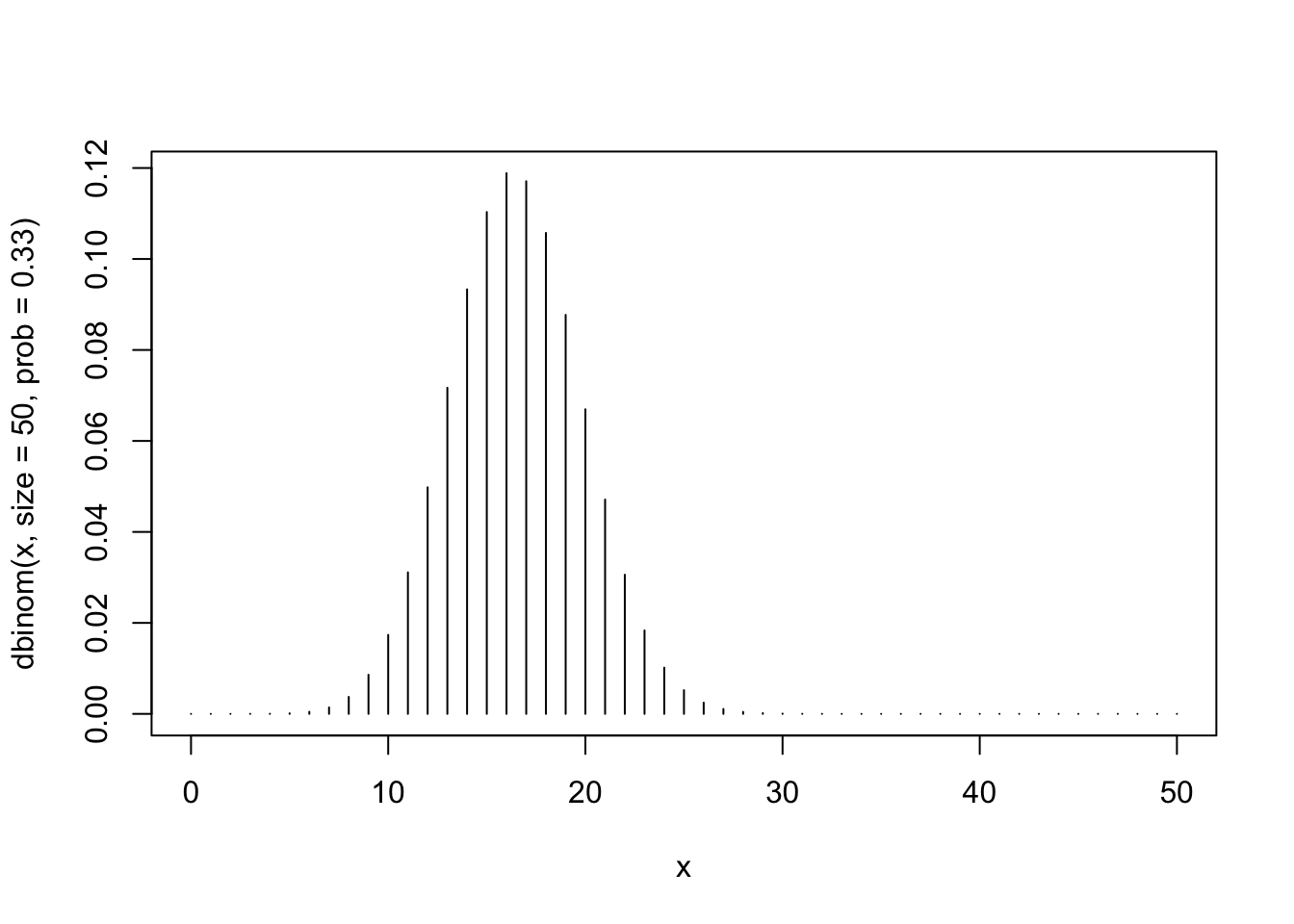
Bu örnekte olduğu gibi dbinom() fonksiyonunda x’e ilaveten n, yani örneklem büyüklüğü ve p, yani olasılık değeri belirtilmelidir. Bu arada x <- 0:50 ifadesi x <- seq(0,50,1) ifadesinin kısa şeklidir, type=”h” parametresi çubuk grafik çizmemizi sağlar.
Birikimli (cumulative) yoğunluk fonksiyonu
Birikimli yoğunluk fonksiyonu x veya x’den daha küçük bir değer elde etme ihtimalini verir. Birikimli yoğunluk fonksiyonunu grafik olarak göstermek pek faydalı değildir. Bunun yerine sayı olarak ifadesi daha doğru bilgi verir. Mesela, suça maruz kalmış kişilerin haftalık olarak evleri dışında geçirdikleri saat ortalamasının 48, standart sapmasının 3 olduğunu düşünürsek, şayet bir kişi haftada ortalama olarak 57 saatini dışarıda geçiriyorsa pnorm() fonksiyonuyla;
1-pnorm(57,mean = 48,sd = 3)## [1] 0.001349898örneklemin sadece %0.1’inin bu kişiyle aynı veya daha yüksek bir değere sahip olduğunu bulabiliriz. Görüldüğü gibi pnorm() fonksiyonu, fonksiyona giren ilk değerden daha düşük bir değer elde etme ihtimalini vermektedir. Bunu birden çıkarttığımızdaysa fonksiyona giren ilk değere eşit veya daha yüksek değerlerin ihtimalini elde ederiz.
Birikimli yoğunluk fonksiyonu genellikle istatistiksel testlerde kullanılabilir. Örnek olarak iki farklı tedavi (A ve B) uygulanan 20 hastadan 16’sının A tedavisini tercih ettiğini varsayalım. Acaba bu sonuç B tedavisinin daha isabetli olduğunu ispatlar mı yoksa bu sonuç şans eseri olabilr mi? Şayet iki tedavi şekli arasında bir fark yoksa A tedavisini tercih eden hastaların p=0.5 ihtimalli bir binomyal dağılıma sahip olmaları gerekir. Yukarıdaki sonucun ne ölçüde mümkün olduğunu birikimli yoğunluk fonksiyonuyla hesaplayabiliriz:
1-pbinom(15, size = 20, prob = .5)## [1] 0.00590896616 kişi A tedavisini tercih etmesine rağmen pbinom() fonksiyonunda 15 değerini kullandık çünkü bu sayede 16 değerinden daha küçük değerlerin yoğunluk fonksiyonunu hesaplamış olduk. Dolayısıyla bu sonucun şans eseri çıkma ihtimalinin %0.5 olduğunu görüyoruz. Eğer iki yönlü test yapacaksak, yani A mı yoksa B mi daha fazla tercih edildi bilmiyorsak;
1-pbinom(15, size = 20, prob = .5) + pbinom(4, size = 20, prob = .5)## [1] 0.01181793Burada artı işaretinden sonraki kısımda ilk kısmın tam tersi durumun ihtimalini yani 16 kişinin B tedavisini tercih etme durumunu hesaplamış olduk. Bu durumda şans eseri böyle bir sonuç alma ihtimali %1.2 olmakta. Son iki hesaplama için R’da binom.test() isimli özel bir fonksiyon bulunmaktadır:
binom.test(16,20,.5,alternative = "greater")##
## Exact binomial test
##
## data: 16 and 20
## number of successes = 16, number of trials = 20, p-value = 0.005909
## alternative hypothesis: true probability of success is greater than 0.5
## 95 percent confidence interval:
## 0.5989719 1.0000000
## sample estimates:
## probability of success
## 0.8Burada alternative parametresiyle testin yönünü belirleyebiliyoruz, ayrıca conf.level parametresi ile istediğimiz bir güven aralığı da belirleyebiliriz.
###Quantile
Quantile fonksiyonu birikimli yoğunluk fonksiyonunun tersini verir. Birikimli yoğunluk fonksiyonuyla belli bir değerin veya bu değerden daha düşük bir değerin elde edilme ihtimalini bulabiliyorduk. Quantile fonksiyonuyla ise belli bir ihtimalin hangi değere isabet ettiğini bulabiliriz.
qnorm(.025); qnorm(.975)## [1] -1.959964## [1] 1.959964Yani normal dağılım eğrisinin solundaki %2.5’luk kısım -1.95 değerine, sağındaki %2.5’luk kısım ise 1.95 değerine denk düşmektedir. Bu değerleri kullanarak haftalık ev dışında geçirdikleri saat ortalaması 48, standart sapması 3 olan 10 kişiye ait %95 güven aralığını şu şekilde bulabiliriz:
sem <- 3/10
48 + sem * qnorm(.025)## [1] 47.4120148 + sem * qnorm(.975)## [1] 48.58799Bu örnekte ilk önce ortalamanın standart hatasını (standart error of mean – sem) hesapladık. Daha sonra bunu kullanarak dağılım eğrisinin her iki ucundaki %2.5’luk kısmın hangi değere isabet ettiğini bulduk. Dolayısıyla örneklemin %95’i, 47.41 ile 48.59 arasında bulunuyor, yani gayet sık bir veriseti.
Rastgele Sayılar
R ile farklı istatistiksel dağılımlara sahip rastgele sayılar üretmek mümkündür. Yalnız bilgisayar yardımıyla üretilen sayıların tam anlamıyla rastgele sayı olmayacağı akıldan çıkartılmamalıdır. Bu yüzden bunlara ‘pseudo-random’ yani ‘rastgele gibi’ sayılar diyoruz. Rastgele sayılar simülasyon çalışmalarında kullanılmaktadır. En sık kullanılan dağılım türü olan normal dağılıma sahip rastgele sayılar üretmek için rnorm() fonksiyonu kullanılır. Bir önceki örnekte kullandığımız ortalaması 48, standart sapması 3 olan 10 tane rastgele sayı üretip histogram grafiğini çizelim:
x <- rnorm(10, mean = 48, sd = 3)
hist(x, xlim = c(35,65))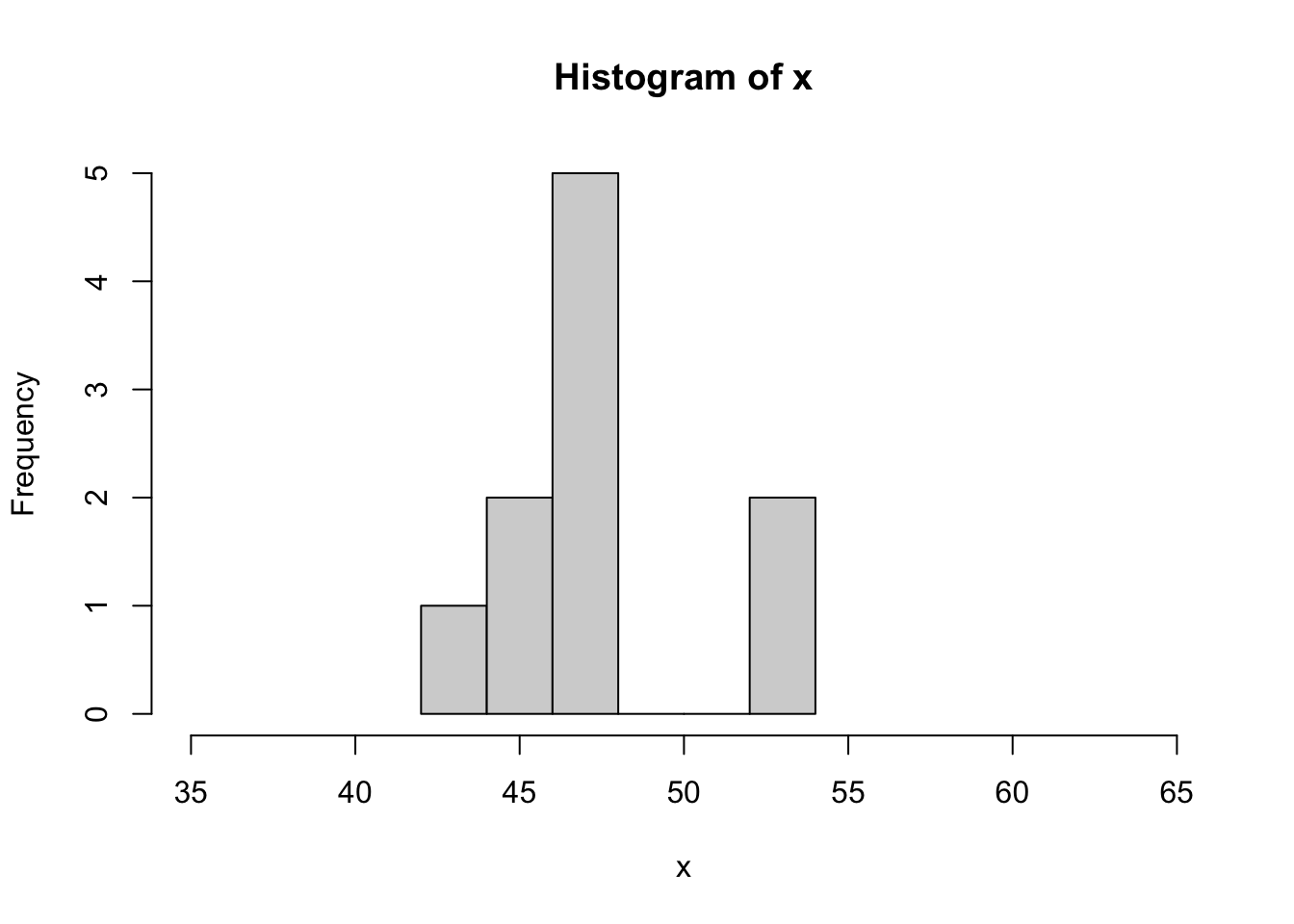
Aynı şekilde binomyal dağılım elde etmek istiyorsak rbinom() fonksiyonu kullanabiliriz:
rbinom(10, size = 20, prob = .3)## [1] 5 6 1 3 3 9 4 5 4 7rbinom(10, size = 20, prob = .5)## [1] 7 11 9 6 14 9 10 6 11 10rbinom(10, size = 20, prob = .8)## [1] 18 15 16 16 14 16 15 16 17 16Farklı olasılık değerlerinde rastgele sayıların da değiştiğini gözlemleyebiliriz.
Bu yazıda Peter Dalgaard’ın “Introductory Statistics with R” isimli kitabından faydalandım.