Çok değişkenli regresyon modeli
Bir önceki yazıda doğrusal regresyonun temel mantığını, analiz sonuçlarının nasıl yorumlandığını ve analizin R ortamında nasıl yapıldığını anlattık. Analiz mantığını kavrayabilmek için tek bir bağımsız değişken içeren iki model hesapladık. İlk modelde iki değerli (binary) bir bağımsız değişken ve ikinci modelde sürekli değerler içeren bir bağımsız değişken kullanarak regresyon analizinin temelde değişkenlerin ortalama değerlerinin karşılaştırmasından ibaret olduğunu göstermeye çalıştık.
Bu yazıdaysa birden fazla değişken olması halinde analizin nasıl yapıldığı ve ne şekilde yorumlanacağını inceleyeceğiz. Bu yazıda A. German ve J. Hill’in, Data Analysis Using Regression and Multilevel/Hierarchical Models kitabının üçüncü bölümünde yer alan örneği dikkatinize sunacağım. Kitapta yer alan verisetleri ve kullanılan R kodlarını burada bulabilirsiniz.
Bu örnekte kidiq isimli verisetini kullanacağız. Verisetinde 434 çocuğa ait IQ test skorları ve bu çocukların annelerine ilişkin bazı veriler bulunmakta. İlk modelimizde çocuğun IQ skorunun, annenin lise mezunu olup olmamasıyla (0=lise mezunu değil, 1= lise mezunu) ve annenin IQ seviyesiyle ilişkili olup olmadığına bakacağız:
library(foreign)
kidiq <- read.dta("kidiq.dta")
attach(kidiq)
fit.2 <- lm (kid_score ~ mom_hs + mom_iq)
fit.2##
## Call:
## lm(formula = kid_score ~ mom_hs + mom_iq)
##
## Coefficients:
## (Intercept) mom_hs mom_iq
## 25.7315 5.9501 0.5639Öncelikle verisetini R ortamına aktarmamız gerekiyor. A. German ve J. Hill’in çalışmasında veriseti STATA formatında kaydedilmiş olduğundan öncelikli olarak foreign paketini sisteme yükledik ve read.dta() fonksiyonuyla versetini aktardık. Değişken isimlerini daha rahat kullanabilmek için attach() fonksiyonuyla verisetini R ile ilişkilendirdik. Ardından regresyon modelimizi hesapladık. Çıkan modeli şu şekilde ifade edebiliriz:
Çocuğun IQ Skoru = 25,73 + 5,95 Annenin lise durumu + 0,56 Annenin IQ skoru
Dolayısıyla bu modele göre annenin lise mezunu olmasının çocuğun IQ seviyesi üzerinde daha büyük bir etkisi var. Kesim noktası annesi lise bitirmemiş ve IQ seviyesi 0 puan olan bir çocuğun IQ skorunu ifade etmekte (ki çok anlamlı değil). Anneleri aynı IQ seviyesine sahip çocukları karşılaştırdığımızda, anneleri lise bitirmiş çocukların IQ skorları yaklaşık 6 puan daha yukarıda. Anneleri lise bitirme açısından aynı durumda olan çocuklar arasında, annenin IQ skorunun bir birim artışı çocuğun IQ skoruna sadece yarım puan (0,56) kadar bir etki yapmakta.
Lise bitirmiş ve bitirmemiş annelerini çocuklarının IQ skorlarını aşağıda yer alan grafikte daha rahat karşılaştırabiliriz. Önce grafiğin çizilişine bakalım:
plot(mom_iq,kid_score, xlab="Mother IQ score", ylab="Child test score",pch=20, xaxt="n", yaxt="n", type="n")
curve (coef(fit.2)[1] + coef(fit.2)[2] + coef(fit.2)[3]*x, add=TRUE, col="blue")
curve (coef(fit.2)[1] + coef(fit.2)[3]*x, add=TRUE, col="red")
points (mom_iq[mom_hs==0], kid_score[mom_hs==0], col="red", pch=19)
points (mom_iq[mom_hs==1], kid_score[mom_hs==1], col="blue", pch=19)
axis (1, c(80,100,120,140))
axis (2, c(20,60,100,140))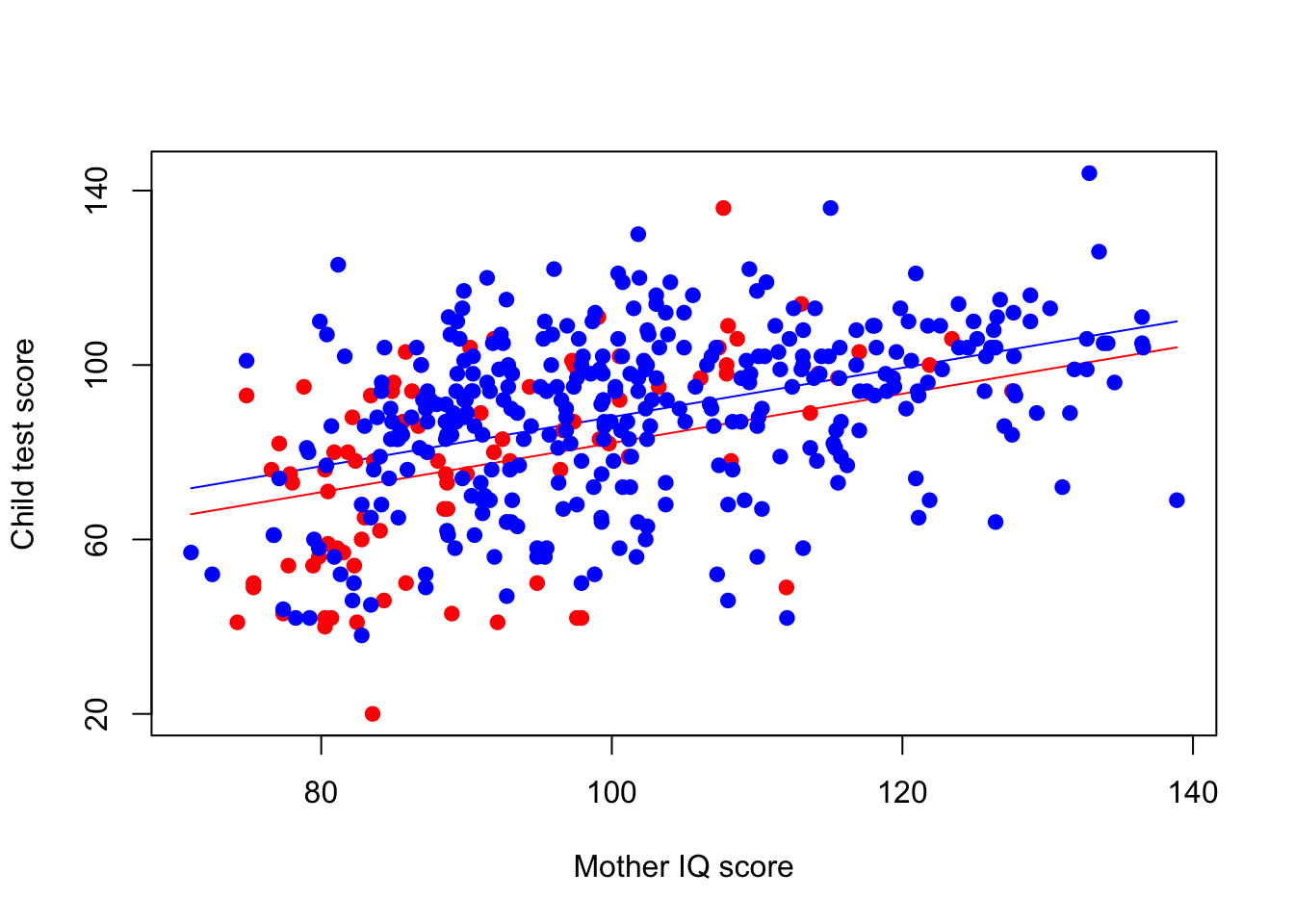
Yukarıdaki R kodunda ilk önce plot() fonksiyonuyla grafik alanını boş olarak çizerek eksen etiketlerini yerleştirdik. Bir önceki yazıda regresyon hattını abline() fonksiyonuyla çizmiştik. Şimdiyse verilen bir fonksiyona ait eğriyi çizmeye yarayan curve() fonksiyonunu kullanıyoruz. Regresyon katsayılarını değer olarak girmek için coef() fonksiyonunu kullandık. coef() verilen bir değişkendeki katsayıları ayıklayarak ekrana getirmektedir. coef(fit.2) komutunu girdiğimizde şu çıktıyı almaktayız:
coef(fit.2)## (Intercept) mom_hs mom_iq
## 25.731538 5.950117 0.563906Dolayısıyla coef(fit.2)[1]=25,73, coef(fit.2)[2]= 5,95 ve coef(fit.2)[2]= 0,56 değerlerine sahip.
İlk curve() fonksiyonunda üç katsayı da yer alırken, ikincisinde annenin lise mezunu olması fonksiyonu sıfır olduğundan (lise mezunu olmadığı anlamına gelmekte) fonksiyona dahil edilmedi ve bu şekilde iki regresyon hattı çizildi. Sonraki iki satırda point() fonksiyonuyla annenin lise mezuniyetine göre noktalar mavi ve kırmızı renkle renklendirildi. Son olarak axis() fonksiyonuyla xve y eksenlerine koordinat etiketleri atandı.
Grafikte annelerin ve çocukların IQ skorlarının dağılımı bulunmaktadır. Mavi noktalar lise bitirmiş anneleri gösterirken kırmızı noktalar lise bitirmemiş anneleri simgelemektedir. Aynı şekilde her iki gruba ait regresyon hattı da kendi rengiyle gösterilmektedir. Grafikte görüldüğü üzere anneleri lise bitirmiş çocuklara ait regresyon hattı, anneleri lise bitirmemiş olan çocuklara ait regresyon hattının üzerinde yer almaktadır. Yani anneleri lise bitirmiş çocukların IQ ortalamalarının, anneleri lise bitirmemiş çocukların IQ ortalamalarından daha büyük olduğunu göstermekte.
Regresyon analizinin temel mantığı burada bahsetmeye çalıştığımız gibi “ortalamaların karşılaştırılması” olmakla birlikte, analiz sonuçları yorumlanırken ortalamadan pek bahsedilmez. Genellikle sonuçlar yorumlanırken “diğer değişkenlerin sabit olması şartıyla x’in bir birimlik artışının y üzerinde etkisi şu kadardır” şeklinde bir ifade tercih edilir. Bu örneğe uyarlayacak olursak, “diğer değişken(ler) sabit olmak şartıyla, anneleri lise mezunu olan çocuklar 5,95 puan daha yüksek IQ skoruna sahiptirler” diyebiliriz. Yahut “diğer değişken(ler) sabit olmak şartıyla, annenin IQ skorundaki 1 puanlık artış, çocuğun IQ skorunda 0,56 puan artışı netice vermektedir” diyebiliriz.
Yukarıdaki sonuç çıktısında fit.2 modelinin sadece katsayılarına yer verdik. Daha detaylı çıktıyı summary() fonksiyonuyla görebiliriz:
summary(fit.2)##
## Call:
## lm(formula = kid_score ~ mom_hs + mom_iq)
##
## Residuals:
## Min 1Q Median 3Q Max
## -52.873 -12.663 2.404 11.356 49.545
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 25.73154 5.87521 4.380 1.49e-05 ***
## mom_hs 5.95012 2.21181 2.690 0.00742 **
## mom_iq 0.56391 0.06057 9.309 < 2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 18.14 on 431 degrees of freedom
## Multiple R-squared: 0.2141, Adjusted R-squared: 0.2105
## F-statistic: 58.72 on 2 and 431 DF, p-value: < 2.2e-16Görüldüğü üzere yukarıdaki çıktıda epey bir veri bulunmakta. Bunların izahını sonraki yazılara bırakarak sadece bağımsız değişkenlerin anlamlılık değerlerine dikkat çekelim. Değişkenlerin analiz sonuçlarını gösteren satırların en sağında yer alan yıldızlar her iki değişkenin de istatistiksel olarak anlamlı olduğunu göstermekte.