R ile betimleyici (descriptive) istatistik analizi
Bir veriseti üzerinde çalışırken ilk olarak yapmamız gereken verisetini anlamaktır. Verisetini anlayabilmekse betimleyici (descriptive) istatistik analiz gerektirmektedir. Betimleyici analiz kapsamında neler yapılması gerektiği kişiye ve duruma göre farklılık arzetse de ortalama, medyen, mod standart sapma gibi değerlerin hesaplanması neredeyse standarttır.
Betimleyici analiz için ilk yapılması gereken şey öncelikle verisetinin barındırdığı değişkenleri ve tiplerini incelemek olacaktır. Bu örnekte, R’da bulunan verisetlerinden mtcars veriseti kullanılacaktır.
str(mtcars)## 'data.frame': 32 obs. of 11 variables:
## $ mpg : num 21 21 22.8 21.4 18.7 18.1 14.3 24.4 22.8 19.2 ...
## $ cyl : num 6 6 4 6 8 6 8 4 4 6 ...
## $ disp: num 160 160 108 258 360 ...
## $ hp : num 110 110 93 110 175 105 245 62 95 123 ...
## $ drat: num 3.9 3.9 3.85 3.08 3.15 2.76 3.21 3.69 3.92 3.92 ...
## $ wt : num 2.62 2.88 2.32 3.21 3.44 ...
## $ qsec: num 16.5 17 18.6 19.4 17 ...
## $ vs : num 0 0 1 1 0 1 0 1 1 1 ...
## $ am : num 1 1 1 0 0 0 0 0 0 0 ...
## $ gear: num 4 4 4 3 3 3 3 4 4 4 ...
## $ carb: num 4 4 1 1 2 1 4 2 2 4 ...Veriseti hepsi nümerik değer içeren 11 değişken içermekte. R konsolunda ?mtcars yazarak değişkenlerin neyi ifade ettiğine dair bilgi edinebiliriz. Çıktının ilgili kısmı şu şekilde:
[, 1] mpg Miles/(US) gallon [, 2] cyl Number of cylinders [, 3] disp Displacement (cu.in.) [, 4] hp Gross horsepower [, 5] drat Rear axle ratio [, 6] wt Weight (lb/1000) [, 7] qsec 1/4 mile time [, 8] vs V/S [, 9] am Transmission (0 = automatic, 1 = manual) [,10] gear Number of forward gears [,11] carb Number of carburetors
Değişkenlere ilişkin temel bazı istatistikleri summary() fonksiyonuyla hesaplayabiliriz:
summary(mtcars)## mpg cyl disp hp
## Min. :10.40 Min. :4.000 Min. : 71.1 Min. : 52.0
## 1st Qu.:15.43 1st Qu.:4.000 1st Qu.:120.8 1st Qu.: 96.5
## Median :19.20 Median :6.000 Median :196.3 Median :123.0
## Mean :20.09 Mean :6.188 Mean :230.7 Mean :146.7
## 3rd Qu.:22.80 3rd Qu.:8.000 3rd Qu.:326.0 3rd Qu.:180.0
## Max. :33.90 Max. :8.000 Max. :472.0 Max. :335.0
## drat wt qsec vs
## Min. :2.760 Min. :1.513 Min. :14.50 Min. :0.0000
## 1st Qu.:3.080 1st Qu.:2.581 1st Qu.:16.89 1st Qu.:0.0000
## Median :3.695 Median :3.325 Median :17.71 Median :0.0000
## Mean :3.597 Mean :3.217 Mean :17.85 Mean :0.4375
## 3rd Qu.:3.920 3rd Qu.:3.610 3rd Qu.:18.90 3rd Qu.:1.0000
## Max. :4.930 Max. :5.424 Max. :22.90 Max. :1.0000
## am gear carb
## Min. :0.0000 Min. :3.000 Min. :1.000
## 1st Qu.:0.0000 1st Qu.:3.000 1st Qu.:2.000
## Median :0.0000 Median :4.000 Median :2.000
## Mean :0.4062 Mean :3.688 Mean :2.812
## 3rd Qu.:1.0000 3rd Qu.:4.000 3rd Qu.:4.000
## Max. :1.0000 Max. :5.000 Max. :8.000İhtiyacımız olan değerler burada bulunmuyorsa kendimize göre bir tablo oluşturabiliriz:
ort <- sapply(mtcars[,0:11], FUN=mean)
medyen <- sapply(mtcars[,0:11], FUN=median)
varyans <- sapply(mtcars[,0:11], FUN=var)
stsapma <- sapply(mtcars[,0:11], FUN=sd)
min <- sapply(mtcars[,0:11], FUN=min)
max <- sapply(mtcars[,0:11], FUN=max)
round(cbind(min,max,ort,medyen,varyans,stsapma),digits=2)## min max ort medyen varyans stsapma
## mpg 10.40 33.90 20.09 19.20 36.32 6.03
## cyl 4.00 8.00 6.19 6.00 3.19 1.79
## disp 71.10 472.00 230.72 196.30 15360.80 123.94
## hp 52.00 335.00 146.69 123.00 4700.87 68.56
## drat 2.76 4.93 3.60 3.70 0.29 0.53
## wt 1.51 5.42 3.22 3.33 0.96 0.98
## qsec 14.50 22.90 17.85 17.71 3.19 1.79
## vs 0.00 1.00 0.44 0.00 0.25 0.50
## am 0.00 1.00 0.41 0.00 0.25 0.50
## gear 3.00 5.00 3.69 4.00 0.54 0.74
## carb 1.00 8.00 2.81 2.00 2.61 1.62Önce istediğimiz değerleri hesaplayarak herbirini ayrı bir değişkene atadık. Sonra cbind() fonksiyonuyla bu değişkenleri tablo haline getirdik. Burada kullandığımız round() fonksiyonuyla değerleri yuvarladık ve sadece iki ondalık basamak içermelerini sağladık.
Her defasında bu kadar kod yazmadan da bu işlemi yapabiliriz:
library(moments)
func<-c("min","max","mean","median", "var","sd","skewness","kurtosis")
desc<-matrix(nrow=11,ncol=8)
colnames(desc) <-func
rownames(desc) <-colnames(mtcars)
for(i in 1:length(func)) desc[,i]<-round(sapply(mtcars[,0:11], FUN=func[i]),digits = 2)
desc## min max mean median var sd skewness kurtosis
## mpg 10.40 33.90 20.09 19.20 36.32 6.03 0.64 2.80
## cyl 4.00 8.00 6.19 6.00 3.19 1.79 -0.18 1.32
## disp 71.10 472.00 230.72 196.30 15360.80 123.94 0.40 1.91
## hp 52.00 335.00 146.69 123.00 4700.87 68.56 0.76 3.05
## drat 2.76 4.93 3.60 3.70 0.29 0.53 0.28 2.44
## wt 1.51 5.42 3.22 3.33 0.96 0.98 0.44 3.17
## qsec 14.50 22.90 17.85 17.71 3.19 1.79 0.39 3.55
## vs 0.00 1.00 0.44 0.00 0.25 0.50 0.25 1.06
## am 0.00 1.00 0.41 0.00 0.25 0.50 0.38 1.15
## gear 3.00 5.00 3.69 4.00 0.54 0.74 0.55 2.06
## carb 1.00 8.00 2.81 2.00 2.61 1.62 1.10 4.54Burada bir for döngüsü (loop) kullandık. İlk satırda kullanacağımız fonksiyonların isimlerinden oluşan bir vektör hazırladık. İkinci satırda analiz sonuçlarını depolamak için bir matrix ürettik. Üç ve dördüncü satırlarda matriksin sütun ve satır isimlerini belirledik.
Beşinci satırdaysa döngümüz yer alıyor. Döngünün, yapmak istediğimiz işlem sayısınca tekrar etmesini istiyoruz. Bunun için length(func) parametresini kullandık. Devamında da sapply() fonksiyonuyla hesaplama işlemini yapıp sonucu matrikse sütun olarak kaydediyoruz. Bu kodu ayrı bir yere kaydederek data frame ile ilgili değişiklikler yaparak farklı verisetlerinde kullanabiliriz. Burada kullandığımız skewness() ve kurtosis() fonksiyonları için moments kütüphanesinin yüklenmesi gerekmektedir, library(moments).
Betimleyici istatistik amacıyla yapılan diğer bir analiz değişkenlerin histogram grafiklerini çizmek. Bunun için hist() fonksiyonunu kullanıyoruz:
hist(mtcars$mpg,prob=T,main="Histogram Grafiği", xlab="Yakıt sarfiyatı",col="green")
curve(dnorm(x, mean=mean(mtcars$mpg), sd=sd(mtcars$mpg)), add=TRUE,col="darkblue", lwd=2)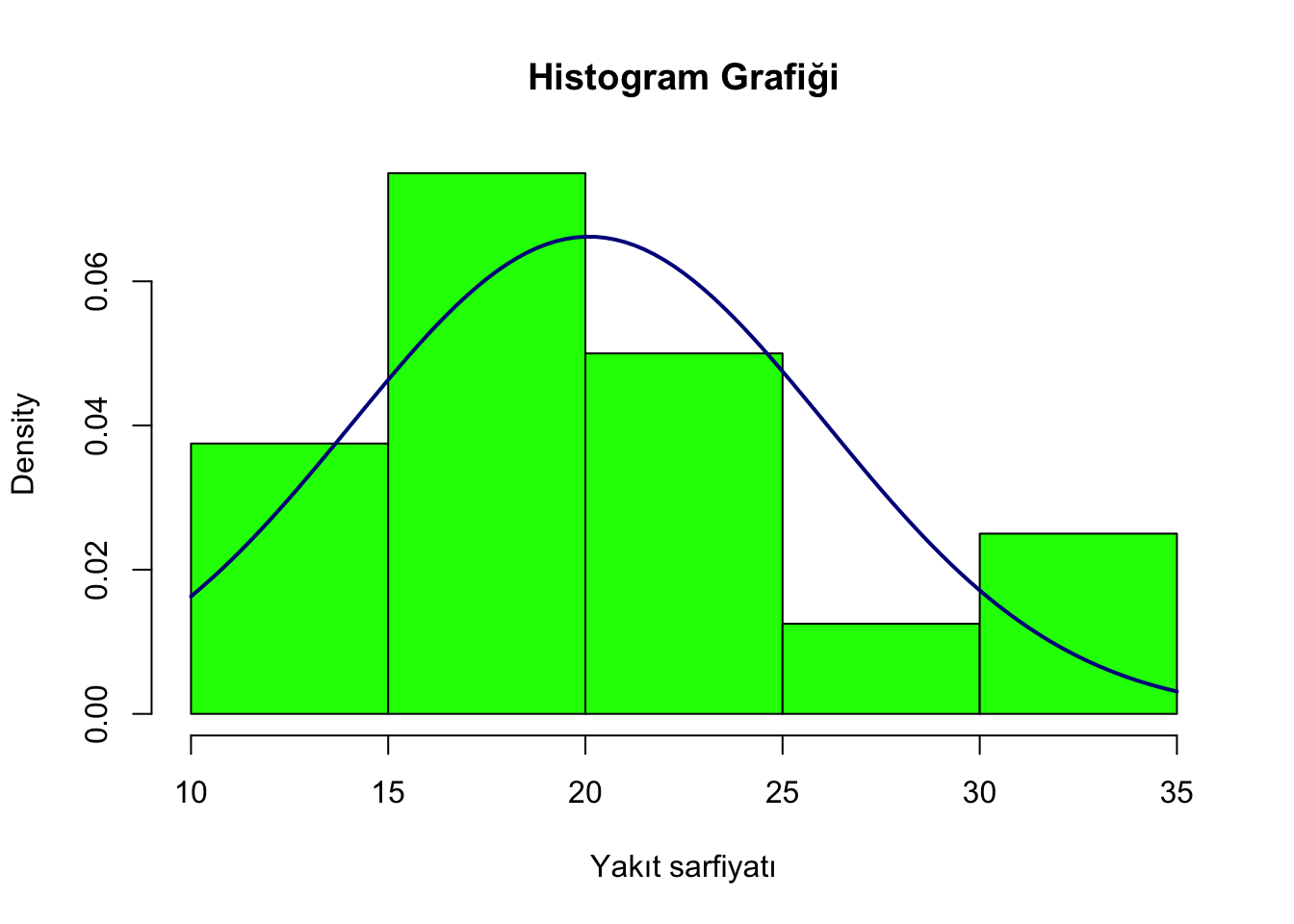
Yukarıdaki kodda ilk satırda histogramı oluşturduk. hist() fonksiyonu ilk parametre olarak histogramını üretmek istediğimiz değişkeni alıyor. prob=TRUE parametresi, y ekseninin sıklık değil ihtimal değerlerini göstermesini istiyoruz. Diğer parametrelerde grafik başlığı ve eksen etiketleri belirlenmekte.
İkinci satırdaki kod ise değişkenin dağılımını gösteren eğriyi grafiğe yerleştirmemizi sağlıyor. Bu yolla değişkenin normal dağılıma sahip olup olmadığını inceleyebiliriz.
Histogram çizerken breaks parametresiyle kesme noktalarını istediğimiz biçimde düzenleyebiliriz. Mesela yaş gruplarına göre kaza geçirme sayılarını veren bir verisetinin histogram eğrisini çizelim. Yalnız histogram sütunlarının alanları, temsil ettiği sayıyla orantılı olsun:
mid.age <- c(2.5,7.5,13,16.5,17.5,19,22.5,44.5,70.5)
acc.count <- c(28,46,58,20,31,64,149,316,103)
age.acc <- rep(mid.age,acc.count)
brk <- c(0,5,10,16,17,18,20,25,60,80)
hist(age.acc,breaks=brk)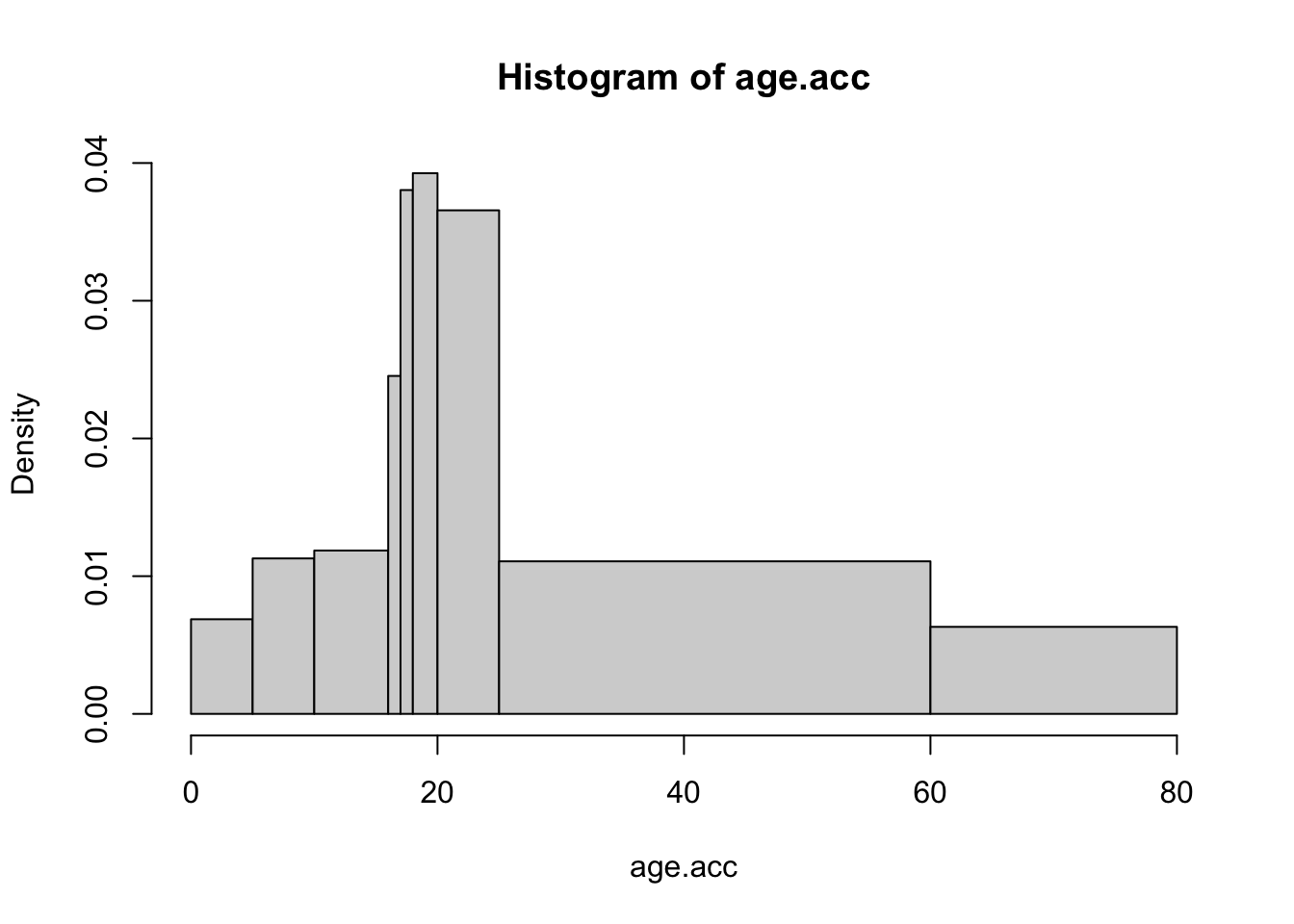
Burada öncelikle mid.age değişkeniyle yaş grupları için ortalama değerleri, ikinci satırda acc.count değişkeniyle herbir gruptaki kişi sayısını belirledik ve üçüncü satırdada ham verisetini oluşturduk. Yani age.acc değişkeninde 28 tane 2.5, 46 tane 7.5 vs. değerleri ürettik. Dördüncü satırda histogramın kesme noktalarını içeren brk vektörünü oluşturduk. Son olarakta histogramı çizdik (Peter Dalgaard, Introductory Statistics with R).
Kullanacağımız değişkenin normal bir dağılıma sahip olup olmadığını incelemek için yapılabilecek hesaplamalardan birisi emprical birikimli fonksiyon (emprical cumulative function) hesaplanmasıdır:
x<-rnorm(50)
n<-length(x)
plot(sort(x),(1:n)/n,type="s",ylim=c(0,1))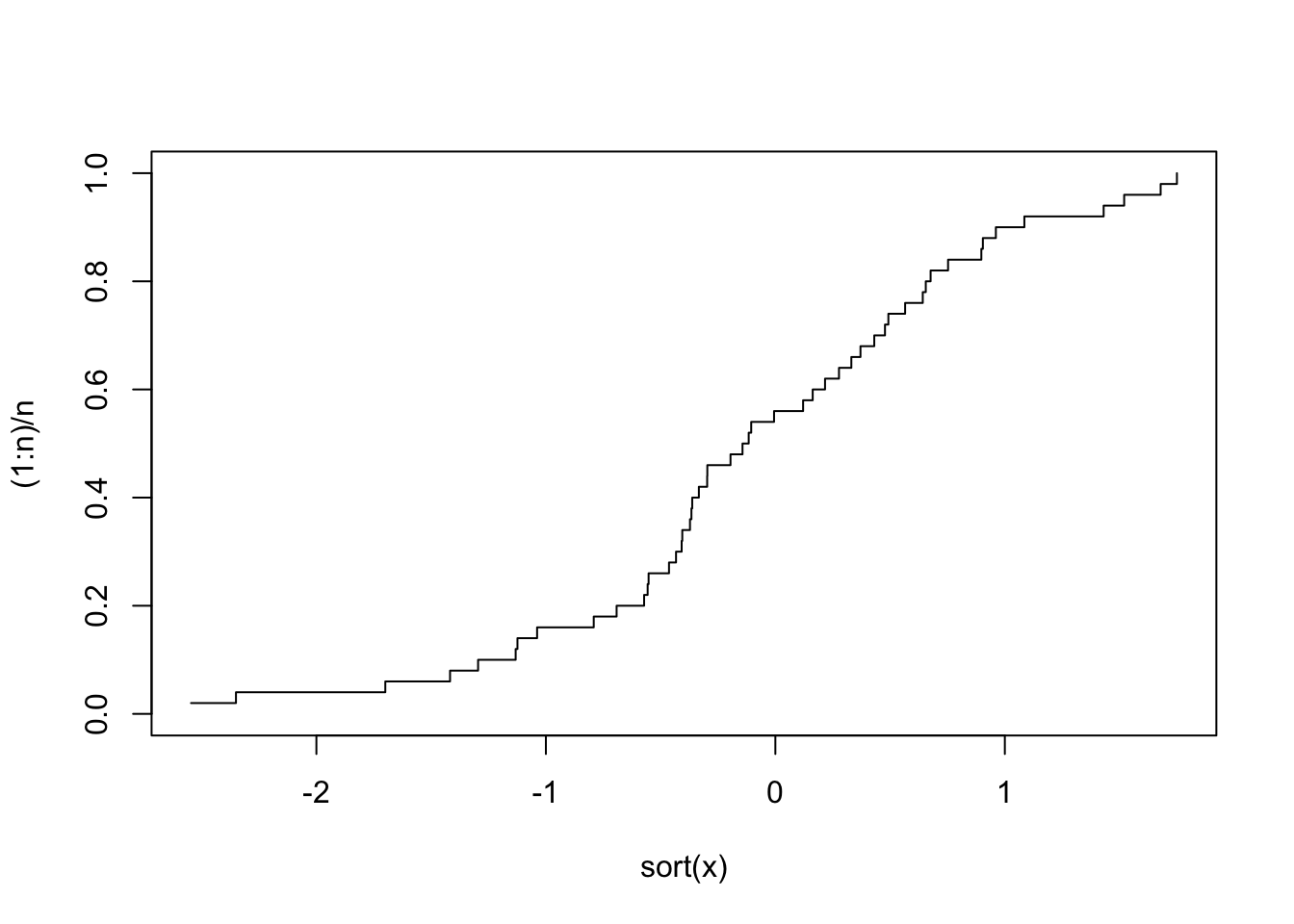
Burada öncelikle 50 tane rastgele sayıdan ibaret bir x vektörü oluşturuyoruz. İkinci satırda n değişkenine değer olarak x vektörünün büyüklüğünü atıyoruz. Üçüncü satırdaysa grafiği çiziyoruz. Dikkat edilirse grafiğin ilk parametresi olarak sort() fonksiyonuyla sıraladığımız x değişkenini, ikinci parametre olarak teoretik dağılımı hesapladığımız bir ifadeyi belirledik. type=”s” parametresiyle basamak şeklinde bir grafik çizdik ve ylim=c(0,1) ile de y eksenini düzenledik (Peter Dalgaard, Introductory Statistics with R).
R ile bu işlemi qqnorm() grafik fonksiyonuyla daha isabetli bir biçimde yapabiliriz.
qqnorm(x)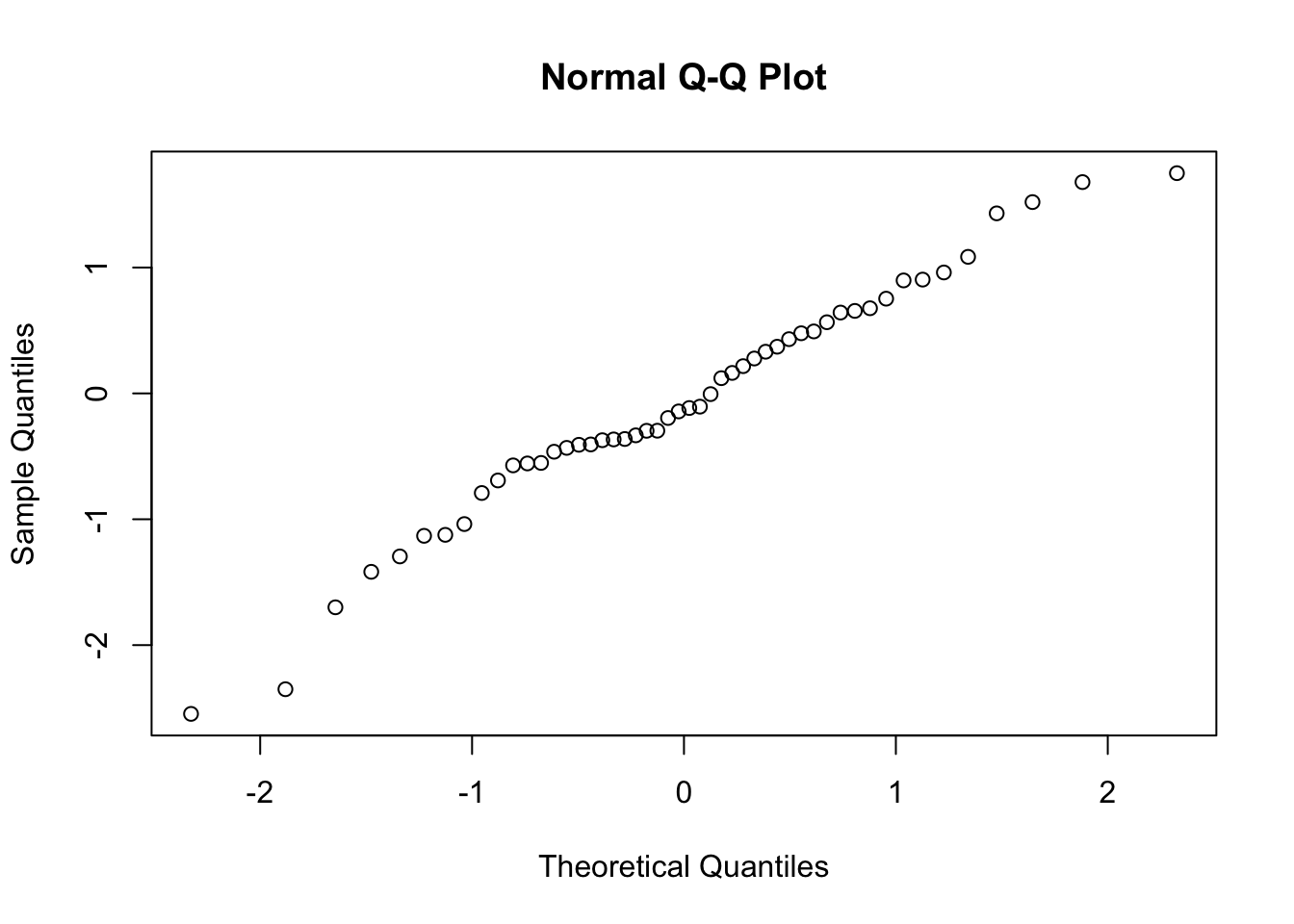
Grafikte y ekseni x değişkenini, x ekseni ise teoretik dağılımı ifade etmektedir. Q-Q Plot grafiğinin düzgün bir eğime sahip oluşu verinin normal dağılıma sahip olduğunu gösterir. Yukarıdaki örnekte uçlardaki düzensizlik verinin alt ve üst değerlerinin normal dağılım özelliği taşımadığını göstermektedir. Aynı biçimde yukarıda kullandığımız mpg değişkenine ait q-q plot grafiğini çizelim:
qqnorm(mtcars$mpg)
qqline(mtcars$mpg)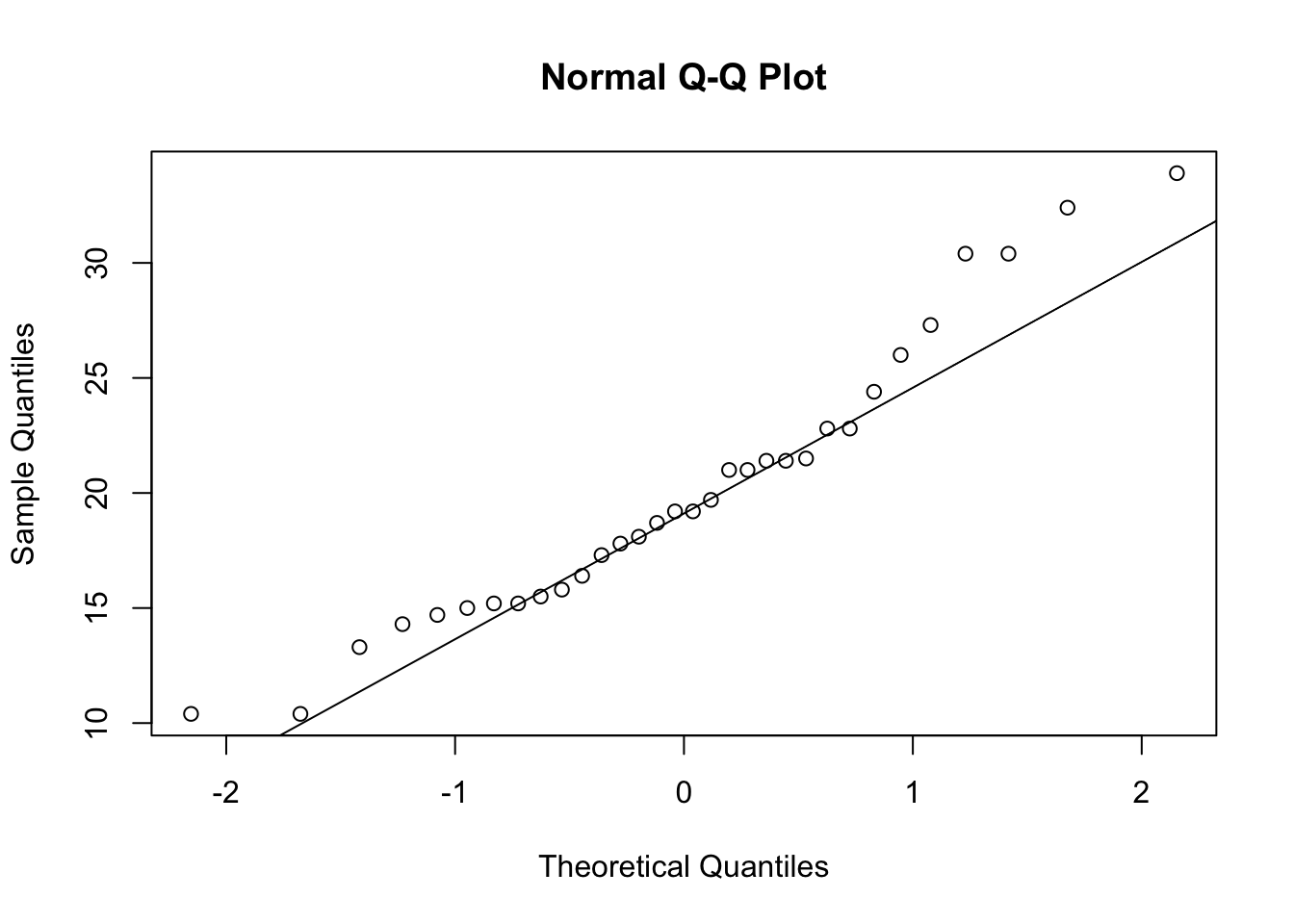
İlk satırda yer alan kod değişkenin dağılım grafiğini oluşturmakta, ikinci satırdaki kod ise değişkenin tamamen normal dağılıma sahip olması durumunda noktaların üzerinde olması gereken hattı çizmektedir. Nadiren bir değişken ikinci satırdaki kod ile çizdiğimiz hat üzerine oturacaktır. Şekildeki grafik değişkenin normal dağılıma yakın olduğunu göstermektedir.
Betimleyici analiz amacıyla çizilebilecek diğer bir grafik dağılım grafiğidir. Dağılım grafiklerini daha önce incelemiştik.
Son olarak, değişkenin dağılımı hakkında bilgi veren skewness ve kurtosis betimsel analizde kullanılan istatistiklerdir. Skewness dağılımın sağa veya sola yatık olup olmadığı, kurtosis ise tekdüze olup olmadığı hakkında bilgi verir. Bunları hesaplayabilmek için moments paketine ihtiyacımız var:
library(moments)
round(sapply(mtcars,skewness),digits=2)## mpg cyl disp hp drat wt qsec vs am gear carb
## 0.64 -0.18 0.40 0.76 0.28 0.44 0.39 0.25 0.38 0.55 1.10Normal dağılıma sahip bir değişkenin skewness değerinin sıfıra yakın olması gerekmektedir. Skewness değerinin pozitif olarak artması, dağılımın sağa doğru uzayan bir kuyruğu olduğunu, negatif olarak artmasıysa sola doğru uzayan bir kuyruğu olduğunu göstermektedir. Yukarıda histogram grafiği bulunan mpg değişkenine baktığımızda skewness değerinin 0.64 olduğunu, bunun grafiği doğruladığını görüyoruz.
Aynı şekilde normal dağılıma sahip bir değişkenin kurtosis değeri sıfıra yakın olacaktır. Kurtosis değerinin pozitif olarak artması dağılımın bir noktada zirve yaptığını, negatif olarak artması düz bir dağılımın olduğunu göstermektedir.